I feel so silly for posting this because you’ll quickly realize that I will have to leave things unfinished for now. But I was so excited that I got something to work, that I had to share!
If you’ve been following along, you know you can always find me here. But I do try my best to cross-post on other channels as well:
But given that everything I do supports the development community, audience statistics are always crucial to me. Because of this, I’ll periodically review my stats on this site and the others to get a feel for the most popular topics.
Python continues to be huge. Really anything Python and REST API related. My Python and Filtering in Queries and Python POST Requests posts seemed to generate A LOT of interest.
I even did a RegEx post a while back that was pretty popular too. Thankfully it wasn’t that popular, as it pained me to work through Regular Expressions.
I can quickly review site statistics on this blog, but other places, like Medium, are more challenging to decipher. Of course, you can download your Audience stats, but sadly not your Story stats 😐.
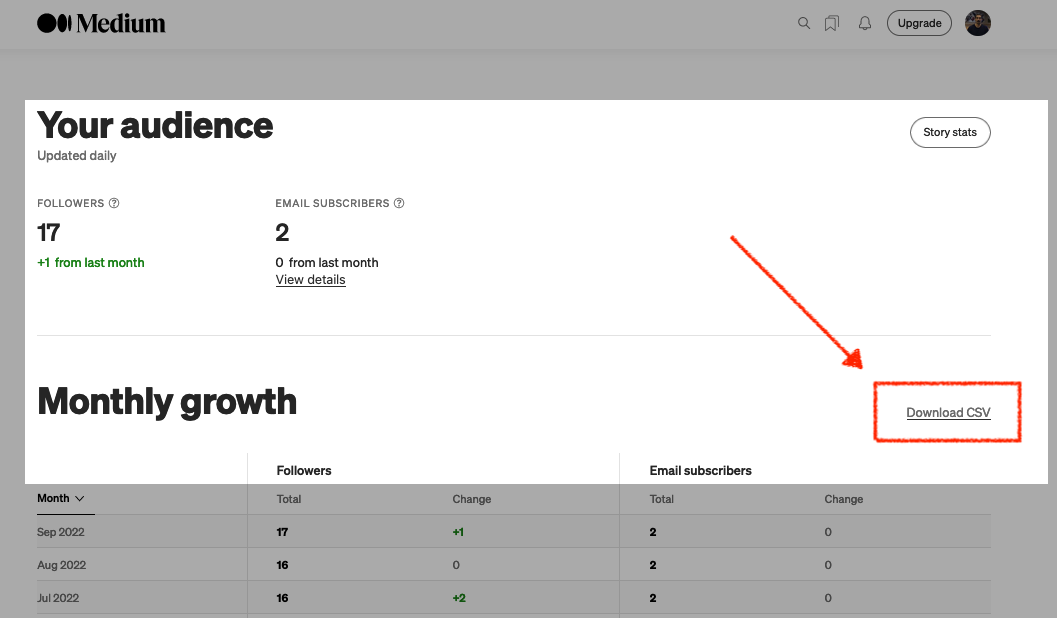
Undeterred, I wanted to see if it was somehow possible to acquire my Story stats. And it is possible, in a way…
Show and tell
If after you log into your Medium account, navigate to your stats page, open up the developer tools in your browser and navigate to your “Console.” From there, reload the page and simply observe all the traffic.
You’ll see a bunch of requests:
GETPOSTOPTION(honestly, I’ve no idea what this is, but I also haven’t looked into it yet)
My thought was that the stats content was produced through (or by) one of these API requests. So yes, I (one at a time) expanded every request and reviewed the Response Body of each request. I did that until I found something useful. And after a few minutes, there it was:
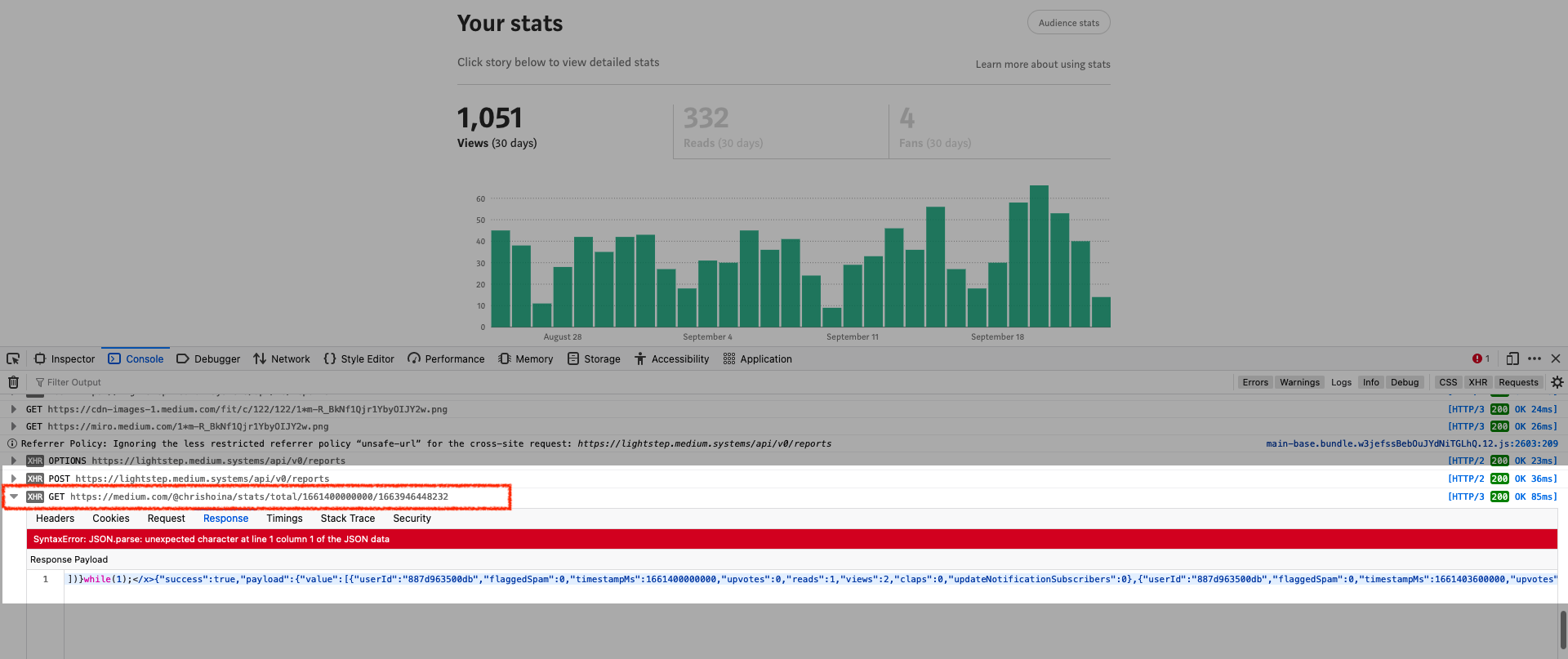
GET request.I confirmed I had struck gold by taking this URL, placing it in a new browser window, and hitting Enter. And after selecting “Raw Data,” I saw this:
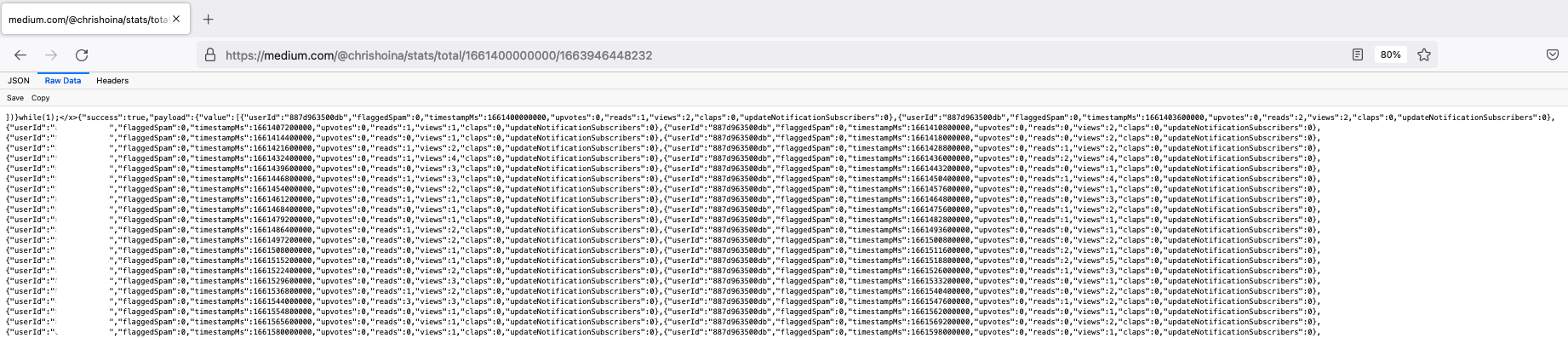
Indeed, we see my Story stats. But the final two paths in the URL made no sense to me.

The paths looked similar; I had no choice but to activate Turing Mode™.
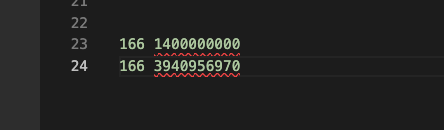
I could see these numbers were similar, so I lined them up in my text editor and saw that they shared the same 166 prefixes. I don’t know much about machine-readable code, but since what was appearing on my screen was the last 30 days, I thought this might be some sort of date. But I’d never seen anything like this, so I wasn’t 100% sure.
Unix Time Stamps
After about 20 mins of searching and almost giving up, I found something in our Oracle docs (a MySQL reference guide of all places) that referenced Unix Time Stamps. Eureka!

Success, I’d found it. So I searched for a “Unix time stamp calculator” and plugged in the numbers. My hunch was correct; it was indeed the last thirty days!
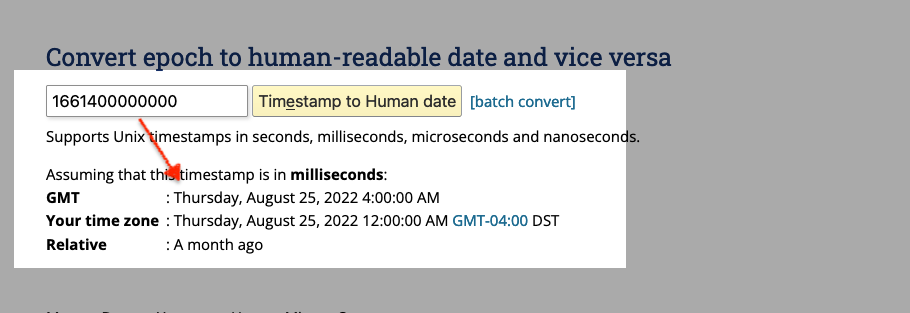
So now I’m wondering if I change that leading date in the GET request will it allow me to grab all my story statistics from January 2022 till now? Oh, hell yeah, it will!

End of the line
Right, so here is where I have to leave it open-ended. I had a finite amount of time to work on this today, but what I’d like to do is see if I can authenticate with Basic Authentication into my Medium account. And at least get a 200 Response Code. Oh wait, I already did that!?
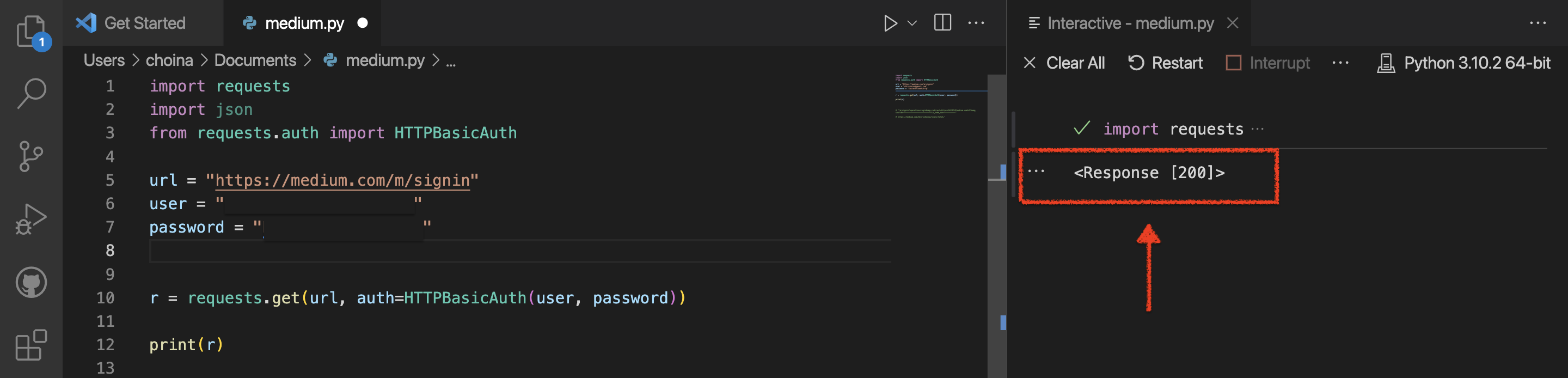
And now the Python code!
import requests
import json
from requests.auth import HTTPBasicAuth
url = "https://medium.com/m/signin"
# I found this to work even if I typically sign on through
# the Google Single-sign-on. I just used the same email/password
# I do when I login directly to google (Gmail).
user = "[Your login/email]"
password = "[Your password]"
r = requests.get(url, auth=HTTPBasicAuth(user, password))
print(r)
# I found this URL in the console but then removed everything after
# the query string (the "?"), and used that for the requests URL
# "/m/signin?operation=login&redirect=https%3A%2F%2Fmedium.com%2F&source=--------------------------lo_home_nav-----------"You’re probably wondering how I found the correct URL for the Medium login page. Easy, I trolled the Console until I found the correct URL. This one was a little tricky, but I got it to work after some adjusting. I initially found this:
"/m/signin?operation=login&redirect=https%3A%2F%2Fmedium.com%2F&source=--------------------------lo_home_nav-----------"And since I thought everything after that “?” was an optional query string, I just removed it and added the relevant parts to Medium’s base URL to get this:
https://medium.com/m/signinNext steps
From here, I’d like to take that JSON object and either:
- use the Python Pandas library to clean up before loading into my Autonomous Database via ORDS, or
- extract the existing JSON (CLOB) with SQL (as was detailed in this Oracle Community forum post)
If I want to keep it as is, I know I can load the JSON with a cURL command and an ORDS Batch Load API with ease. I dropped this into my Autonomous Database (Data Load) to see what it would look like:
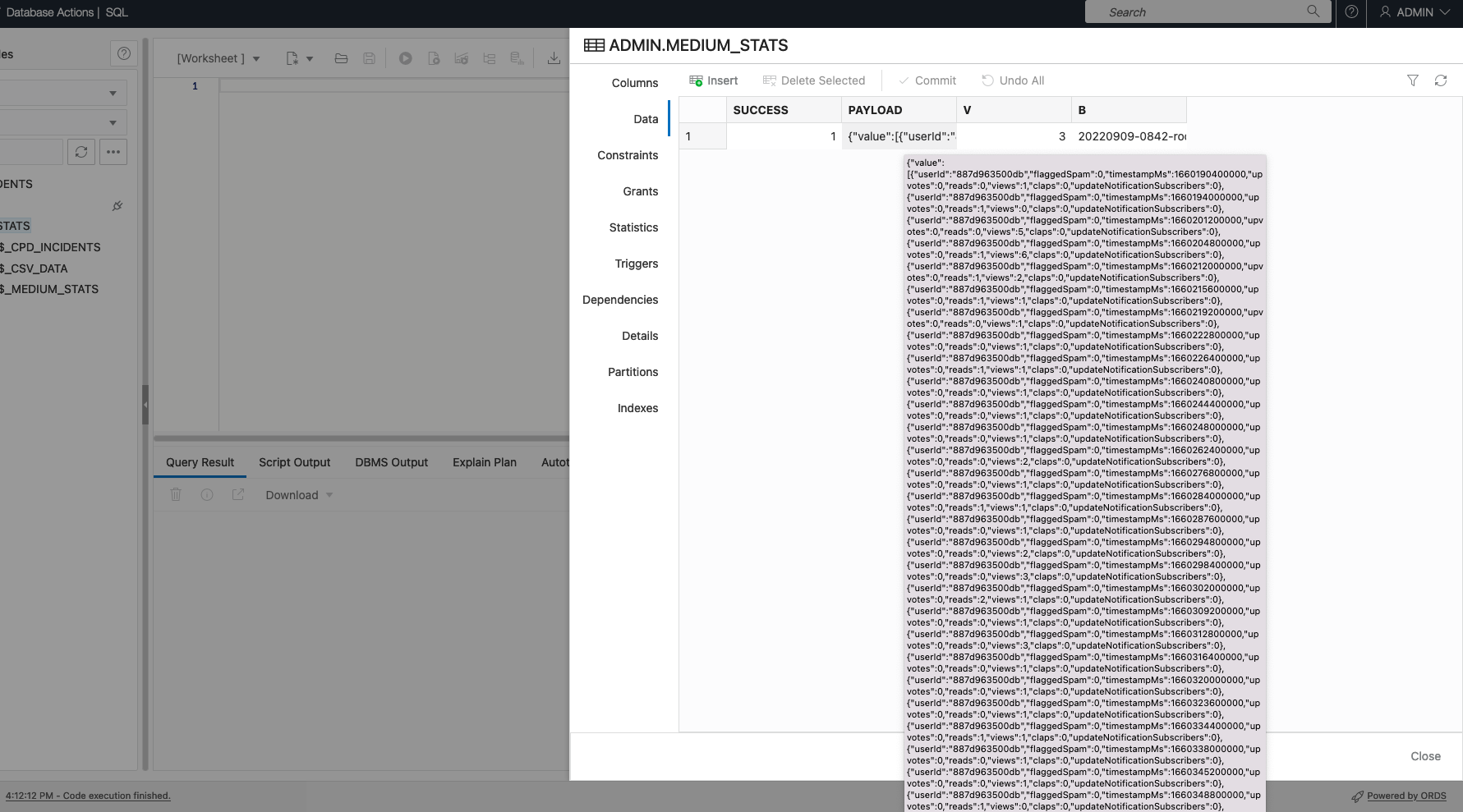
We do something very similar in the Oracle LiveLabs workshop (I just wrote about it here). You can access the workshop here!
I’ll have a follow-up to this. But for now, this is the direction I am headed. If you are reading this, and want to see more content like this, let me know! Leave a comment, retweet, like, whatever. So that I know I’m not developing carpal tunnel for no reason 🤣.
Leave a Reply