About this post
I explore ETags and how they can be used in cURL commands when interacting with Oracle REST APIs. I also discuss some of the performance benefits of using ETags. This is not exhaustive, but I hope it introduces you to ETags or reminds you of their existence! But first…
LATE-BREAKING NEWS!!
A related video
FYI: I reference a CSV_DATA table throughout this post. We use it pretty extensively in this LiveLab. And we just recently presented a webinar based on that same LiveLab. You can check that out below!
About ETags
ORDS supports using Entity Tags, ETags for short.

FYI: We discuss ETags in our ORDS Best Practices, and our bossman Kris Rice has previously experimented with them too!
Don’t know what ETags are? No worries, here is a definition:
The
ETag(or entity tag) HTTP response header is an identifier for a specific version of a resource. It lets caches be more efficient and save bandwidth, as a web server does not need to resend a full response if the content was not changed. Additionally, etags help to prevent simultaneous updates of a resource from overwriting each other (“mid-air collisions”).If the resource at a given URL changes, a new
MDN Web DocsEtagvalue must be generated. A comparison of them can determine whether two representations of a resource are the same.
ETags can help to guarantee the provenance of your resources (like the auto-REST enabled table you’ll see shortly) but they can also ensure your applications consume fewer server/database resources, and load comparatively faster.
To illustrate how ETags work, I did some tinkering with cURL commands, ORDS, and a Podman container. Read on if ye dare…to see what I discovered!
Oracle REST APIs and ETags
A couple of weeks ago, I noticed in the cURL documentation there was support for ETags. And the cURL docs have options for both --etag-save and --etag-compare (practical examples to follow). When you use these options in your cURL commands, you’ll either:
- save an eTag to a separate text file (locally, like on your desktop in my example below), or
- compare the ETag (in that existing file) to an ETag that belongs to your REST-enabled resource (the
CSV_DATAtable, which you’ll see in a second)
Oh, that’s a lot of words! So read it again and then continue with my walkthrough. Meanwhile, I’ll spin up this Podman container.

INFO: Want to learn more about using Podman and Oracle database tools? Check out my other two Podman-related posts here and here!
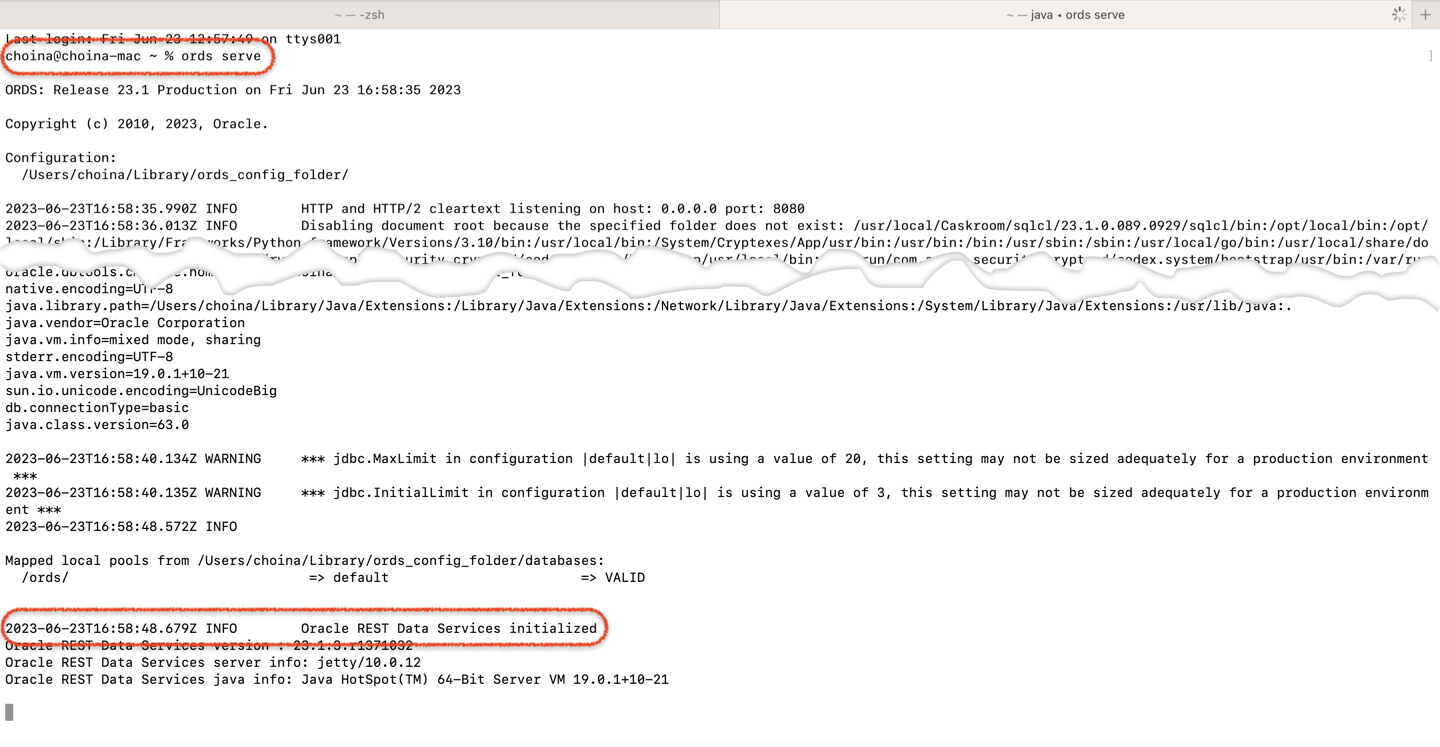
ORDS in Standalone mode
I need ORDS up and running for this demonstration, so I issued the ords serve command in my Terminal. This will launch ORDS in standalone mode (using a Jetty server, as seen in the image). Once it’s initialized, I can log into SQL Developer Web to interact with my database (remember, in this example, it lives in a Podman container).
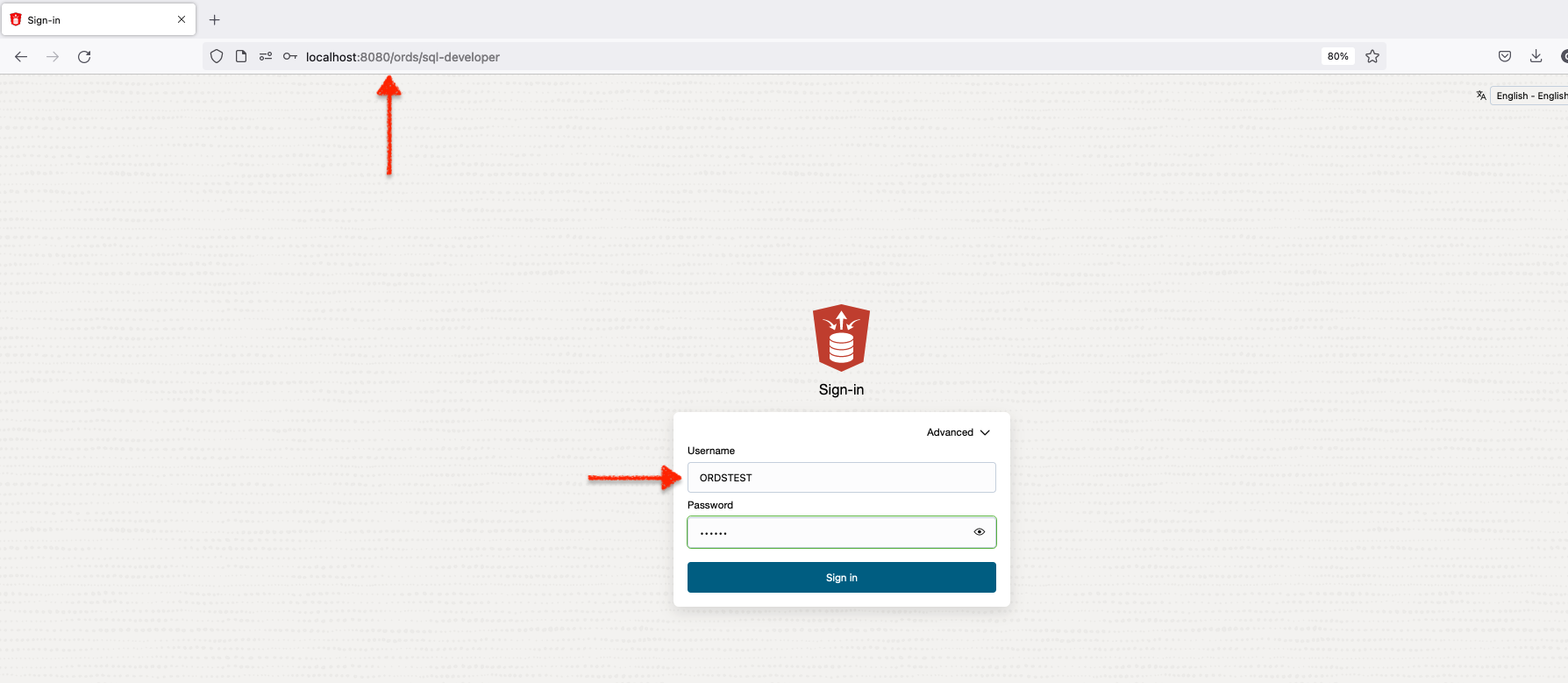
Here, I’ve logged into SQL Developer Web as a non-ADMIN user (ORDSTEST in this case).
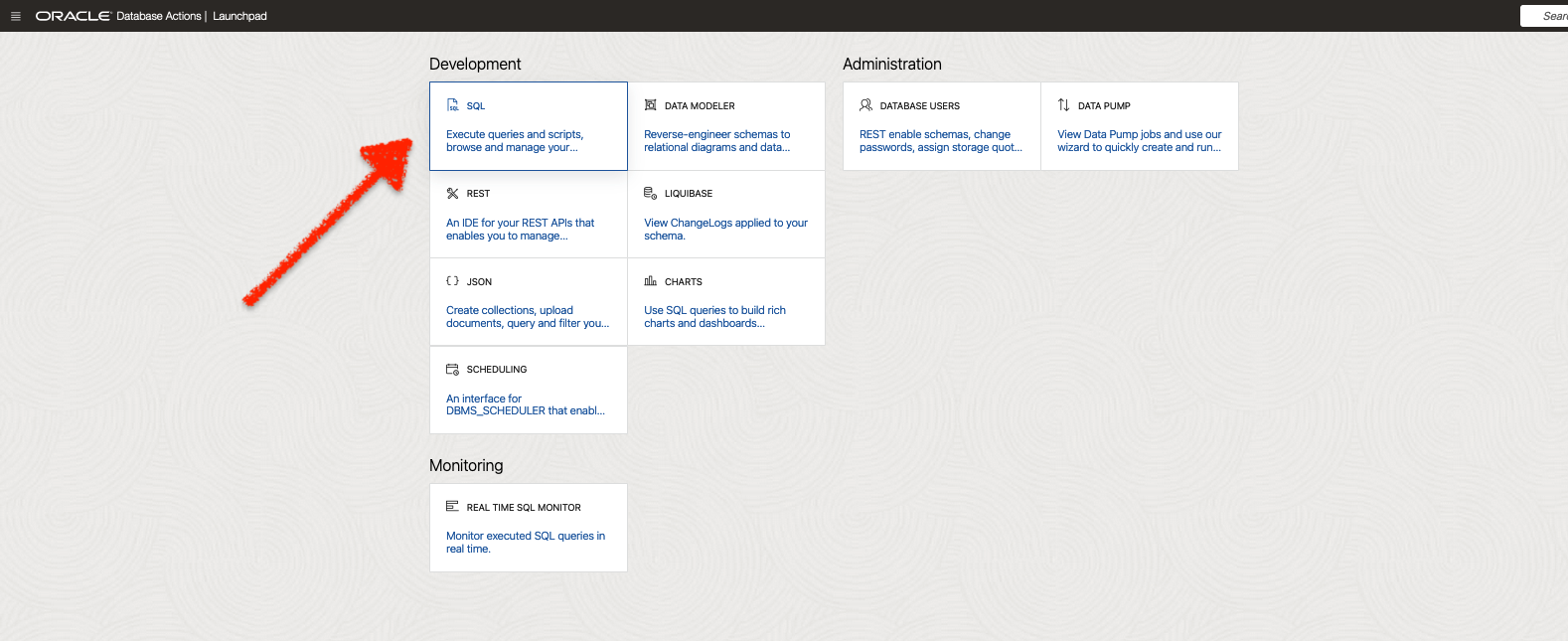
From the Database Actions Launchpad, I navigated to the SQL Worksheet.
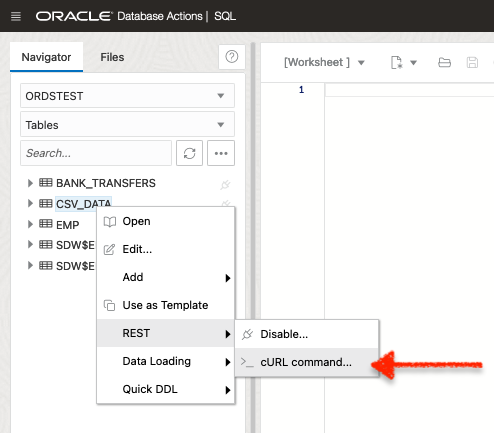
And to keep this quick, I reused a table I created for that webinar we just did. I also auto-REST enabled it (so I could play with the cURL commands). Below, you’ll see it’s just a quick right-click with the mouse.
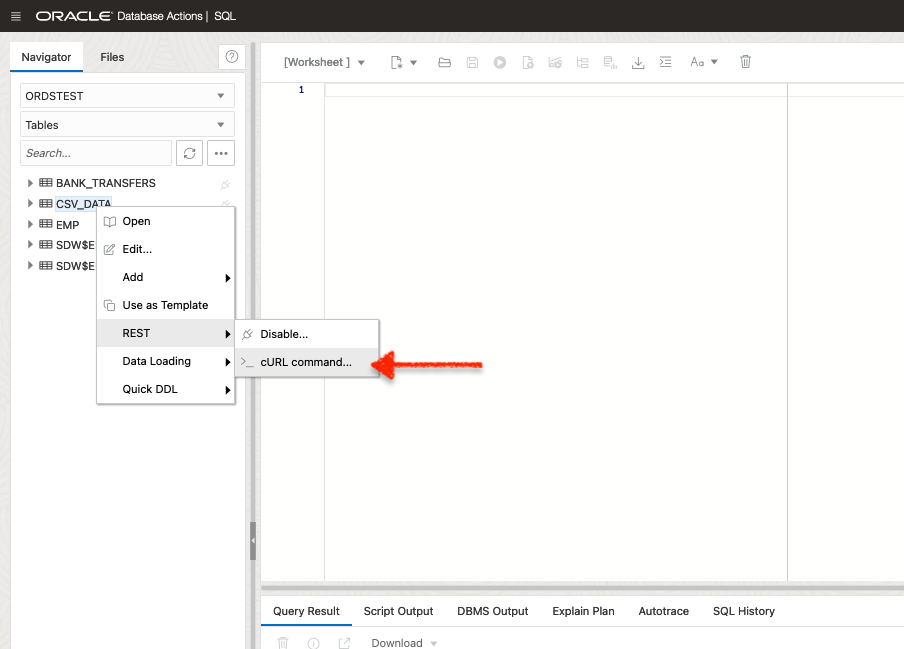
FYI: As a reminder, if you want to learn more about cURL commands, check out the LiveLabs workshop that this is based on. You can find that here.
Getting the cURL Command
Once I auto-REST enabled the CSV_DATA table, I selected the GET ALL REST cURL command.

At this point, I still wasn’t sure that an ETag was sent from the server for those auto-REST-enabled resources (in this case, the CSV_DATA table). I know they are present when you build your own REST Modules with ORDS; (at the time) I was just less confident about the auto-REST resources.
SPOILER ALERT: ETags are present for auto-REST-enabled resources too (I'm dumb, and this is pretty widely known)!
–etag cURL options
Once I knew ETags were accessible for auto-REST-enabled resources, I experimented with cURL‘s --etag options (you’ll see how I implemented these in the upcoming cURL command).
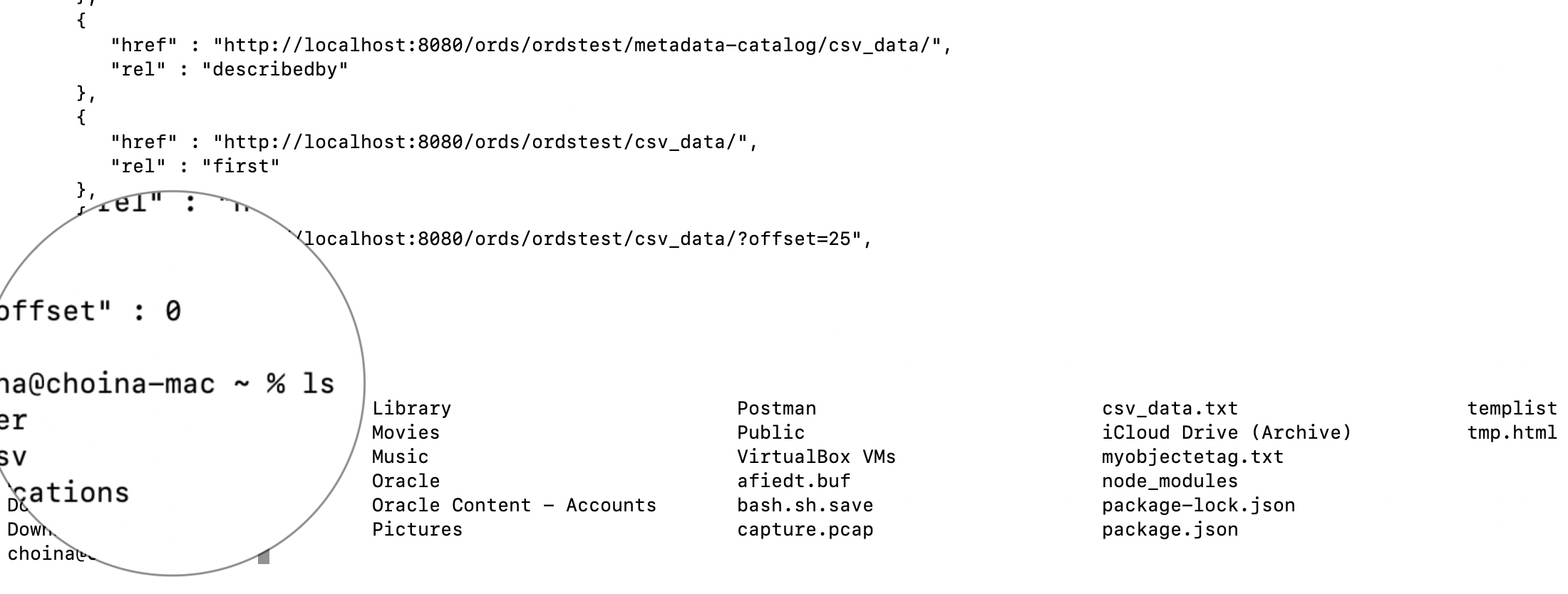
The --etag-save [filename] and --etag-compare [filename] options work such that when you issue the --etag-save in addition to that initial cURL command, a single-line file will be saved to the directory you are currently in (you’ll see that file shortly).
This differs from how an application might work, but the concept is the same. You’re storing the ETag’s value somewhere accessible to the application. For my purposes, I need to keep this ETag somewhere the cURL command line utility can find it.
The initial cURL command
I hopped over to my Terminal and used that [slightly modified] cURL command (the one I previously retrieved from the SQL Worksheet). You’ll see that I included additional options/arguments:
-
--verbose --etag-save| json_pp

FYI: Apparently, the json_pp command utility is a part of Perl. I think this ships with the macOS, but I'm not 100% sure. Do you know? It worked for me and pretty printed out myJSONresponse (notice how I used the pipe "|" in addition to the actual command).
When you use that --etag-save option, a file with the value of the ETag will be saved locally. You can see me retrieving that file and reviewing the ETag file (note in the above cURL command, I named the file “myobjectetag.txt“).

myobjectetag.txt file.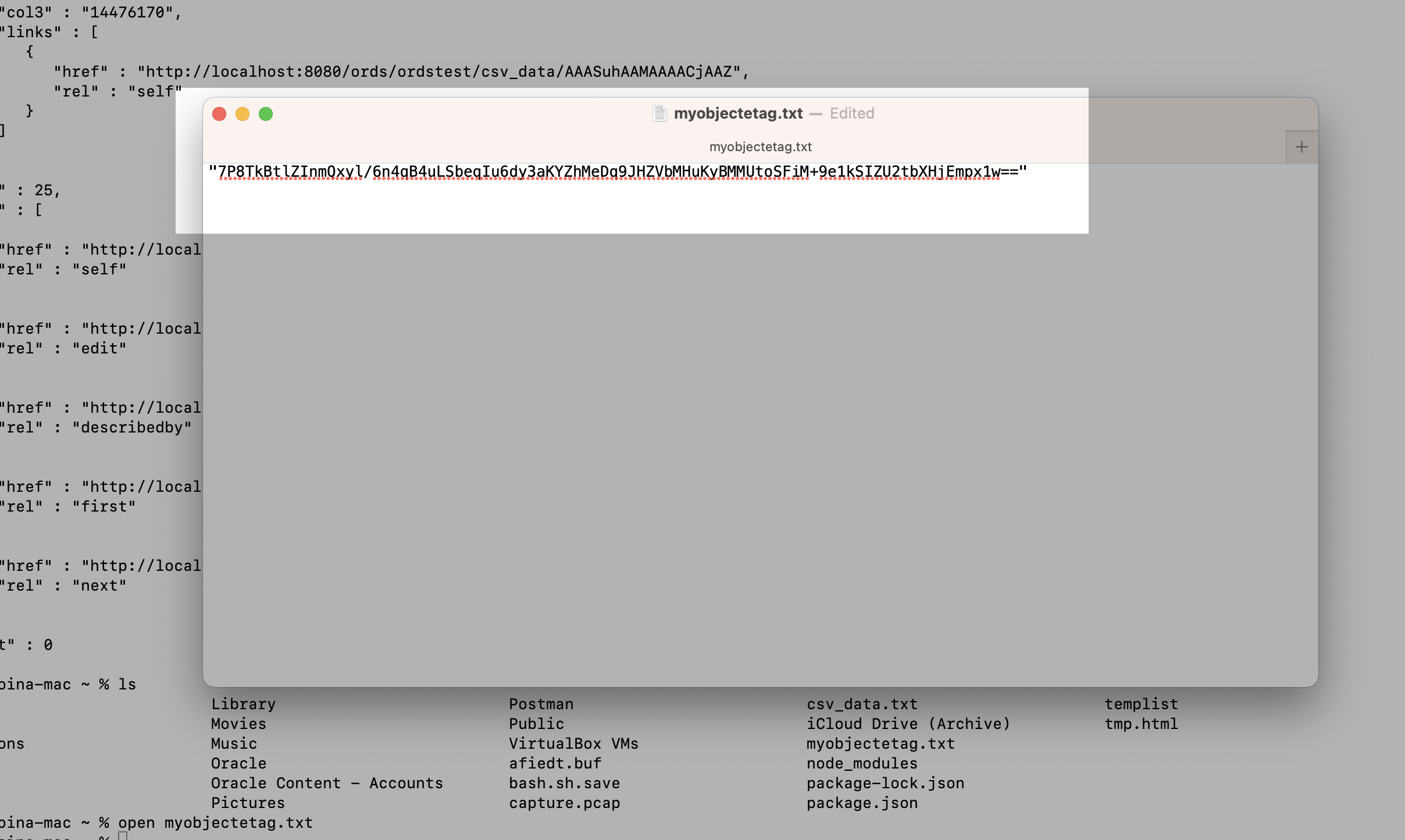
I can now use this ETag in subsequent GET requests to determine if the resource (the CSV_DATA table) I’m requesting has changed since I last interacted with it. What would constitute a change? Maybe rows have been updated or removed; perhaps an additional column was added. Or maybe the table was restructured somehow; it could be any change.
But, let me pause briefly and explain the --verbose option.
About the verbose option
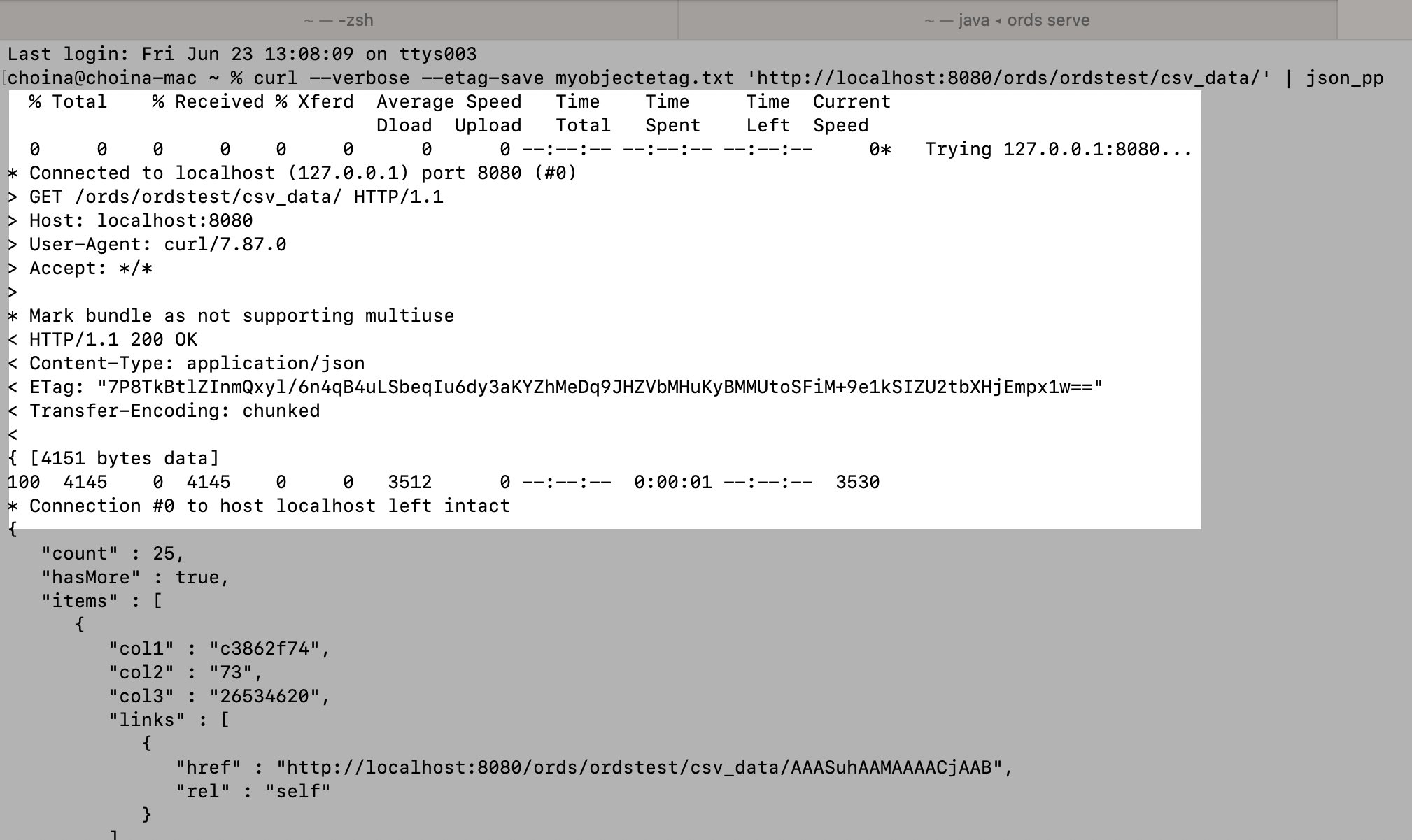
--verbose option.
JSON object is nicely printed out.I used the --verbose option to inspect the information available when interacting with this Oracle REST endpoint. I don’t need to include it now since I know the ETag is coming through, but I left it in this cURL command example so that you could have a look yourself. You’ll see loads of information, including (but not limited to):
- Connection information
- The cURL version used
- The Status Code returned (
200orOKin this case) - ETag info
In this example, all I care about is the presence of an ETag. I can now use that ETag in a subsequent GET request to determine if the resource on the server side has changed. Here is what the cURL command looks like with the --etag-compare option:
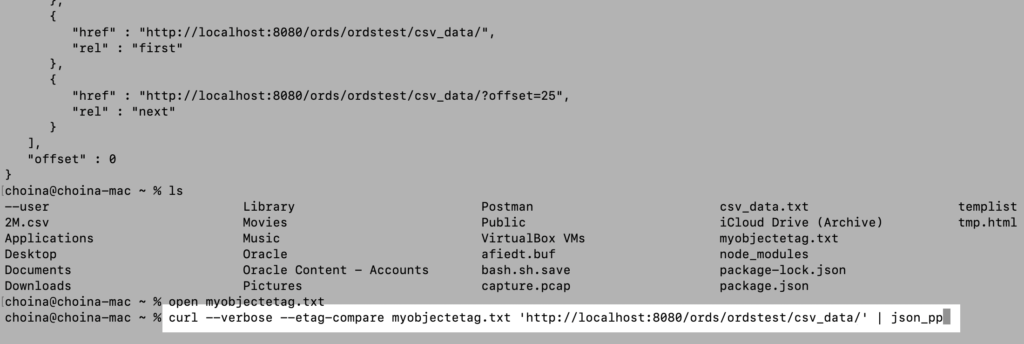
That cURL command looks very similar, except for that --etag-compare option. In this situation, cURL first checks to see if your ETag and the resource’s (the API endpoint on your server) ETag match. If they do, the request stops. And if you use the --verbose option, you can see what comes back from the server:

A whole bunch of nothing. Not really, though. That “If-None-Match” Header is the secret sauce, though. That is a conditional Header that is passed over to the server. Essentially it says, “If this Header value doesn’t match yours, then send over the requested data; otherwise, end the request here because we already have the information we need/. It’s stored/saved (presumably) locally.“
INFO: Read up on caches, because that's essentially what your application is going to use instead of having to go through the entire GET request/response cycle.
The request is terminated, but what does this mean from a performance perspective? Well, say you have a webpage that loads and later reloads in response to a user’s interaction (I simulated this with the two cURL commands). That page will probably need some information from the server to populate that page. In a situation like this, you could first ask your application to share your copy of the ETag with the server in a subsequent GET request header (“If-None-Match“). And if nothing has changed, you could speed up page load times by just refreshing with what you have stored in a cache while freeing up resources on your server for other processes. But this is just one example.
Possibilities with ETag
I’ve given this some thought, and I bet there are quite a few use cases where referring to an ETag before executing an HTTP method (like a GET or GET ALL) might be helpful.
You may want to periodically check to see if a resource has changed since you last interacted with it. Could you incorporate ETags into your build processes or longer-running jobs (maybe something around data analysis)?
Actually, ETags play a massive role in JSON-Relational Duality Views. We have an entire section in the ORDS docs on how to use them! And suppose you want to download a containerized version of the Oracle database 23C (the one that supports JSON-Relational Duality views). You can do that via this link (I think I should do this too and highlight some of the cool ORDS + JSON Duality View features)!
Well, this brings me to the end of this post. I’m hoping you learned something and came away with some good resources. And if you found this post helpful, please pass it along! And don’t be afraid to comment too! I’d love to hear your thoughts. Maybe I’ll even include your idea in a follow-up post 🤩!
Leave a Reply