For…reasons, I needed a way to retrieve all the .CSV files in a regional bucket in Oracle Cloud Object Storage, located at this address:
You can visit it; we use it for one of our LiveLabs (this one), so I’m sure it will stay live for a while 😘. Once there, you’ll see all the available files in that bucket:
FYI: A bucket is one of the three core components of Oracle Cloud's Object Storage. The other two are Objects and Namespaces (more details at Object Storage FAQs).
In this case, there were more than just .CSV files; the script I created will also download those. But, of course, your specific situation may vary. Onto the Python script!
The code
Allow me to first address a few considerations and limitations:
- There is probably a way to create a function that accepts a parameter to make this even more elegant and compact. I’m not “there” yet. So, if you have a better solution, please comment, and I’ll amend my code!
- I still haven’t learned error and exception handling in Python. So anytime you see me “code in”
print(...)that is basically me attempting to check to see if what I think will happen actually happens. - I’m not sure if my
range()andlen()practices are appropriate, but it works, so I’m going with it! - Don’t ask me how I even found out about the
webbrowserlibrary. I must have found it on a forum, or StackOverflow (hate that I can’t attribute credit to my savior).
The code for real
import requests
import json
import webbrowser
url = 'https://objectstorage.us-phoenix-1.oraclecloud.com/n/dwcsprod/b/moviestream_data_load_workshop_20210709/o/'
r = requests.get(url)
data = r.json()
# print(data)
newlist = []
for name in data['objects']:
newlist.append((name['name']))
# print(newlist)
length = len(newlist)
newurl = []
for i in range(length):
newurl = url + newlist[i]
webbrowser.open(newurl, new=0, autoraise=True)As you can see, with spacing, it’s less than 25 lines of code. I’m using a total of three libraries: requests, json, and webbrowser. The first two libraries you are probably familiar with, the third maybe not so much. Webbrowser() is great, when used correctly, the code will automatically open a new browser tab and execute whatever it is told to do (in this case, go to a URL and issue a GET request). Make sense?
Not to worry, I’ll break this down into smaller blocks, to better understand what is happening.
Lines 1-10
import requests
import json
import webbrowser
url = 'https://objectstorage.us-phoenix-1.oraclecloud.com/n/dwcsprod/b/moviestream_data_load_workshop_20210709/o/'
r = requests.get(url)
data = r.json()
# print(data)I’ve imported the three relevant libraries (remember if you don’t have these libraries, you can use pip and perform a pip install to grab them). And I assign URL equal to the target bucket. And from here I perform my first GET request. I do this for two main reasons:
- to remind me of the structure of the JSON, and
- because I am about to loop through all the available files in this bucket (so I need to capture them somehow)
Since I’ve essentially assigned the value of r.json() equal to data, I can now print(data) to visually inspect the….um….data. After executing lines 1-10, I can see the corresponding output in my terminal:
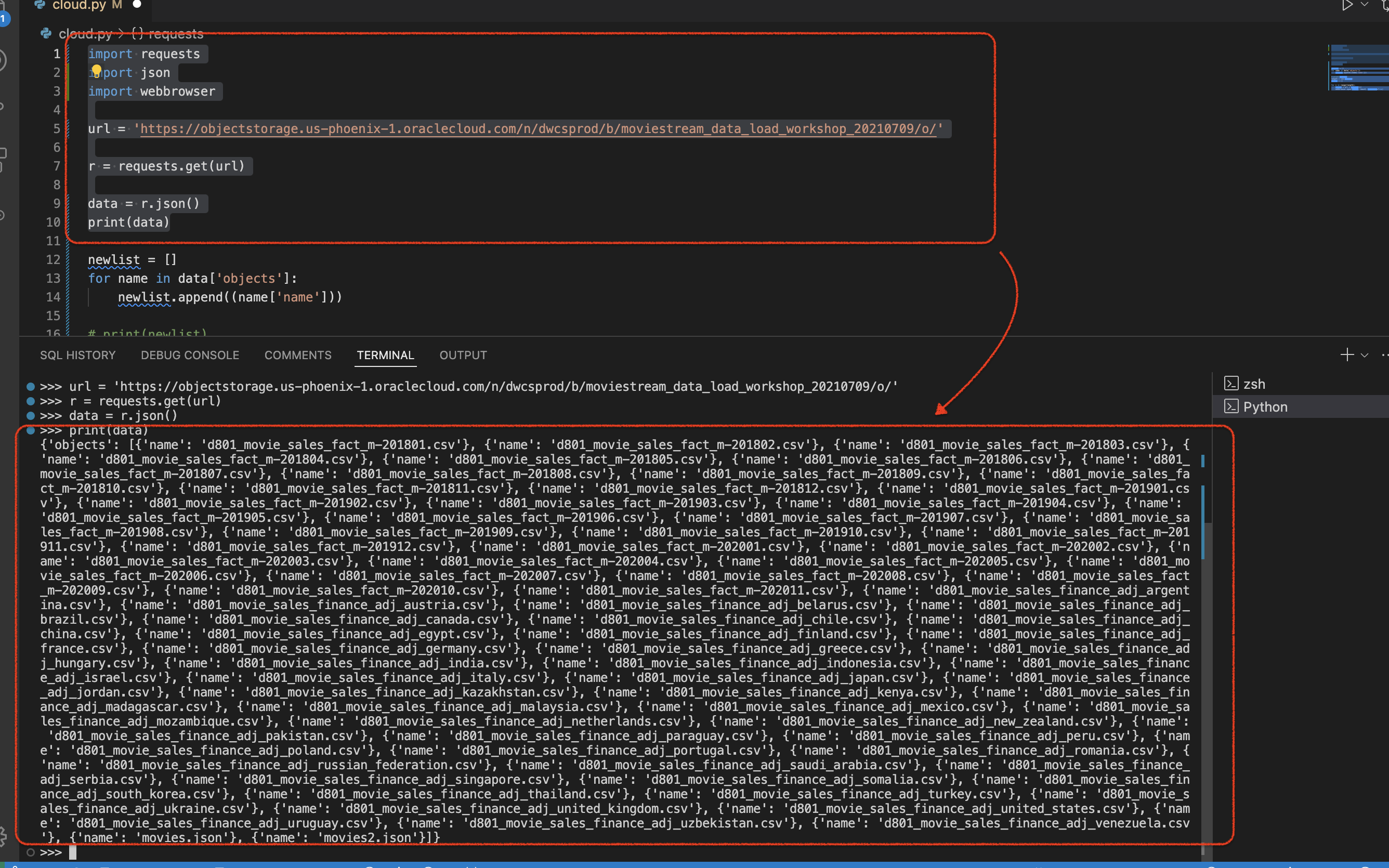
Now that I know this is working (because of my manual check), I can proceed to the next step.
Lines 12-16
Executing this code…
import requests
import json
import webbrowser
url = 'https://objectstorage.us-phoenix-1.oraclecloud.com/n/dwcsprod/b/moviestream_data_load_workshop_20210709/o/'
r = requests.get(url)
data = r.json()
print(data)
newlist = []
for name in data['objects']:
newlist.append((name['name']))
print(newlist)Will yield a new list:
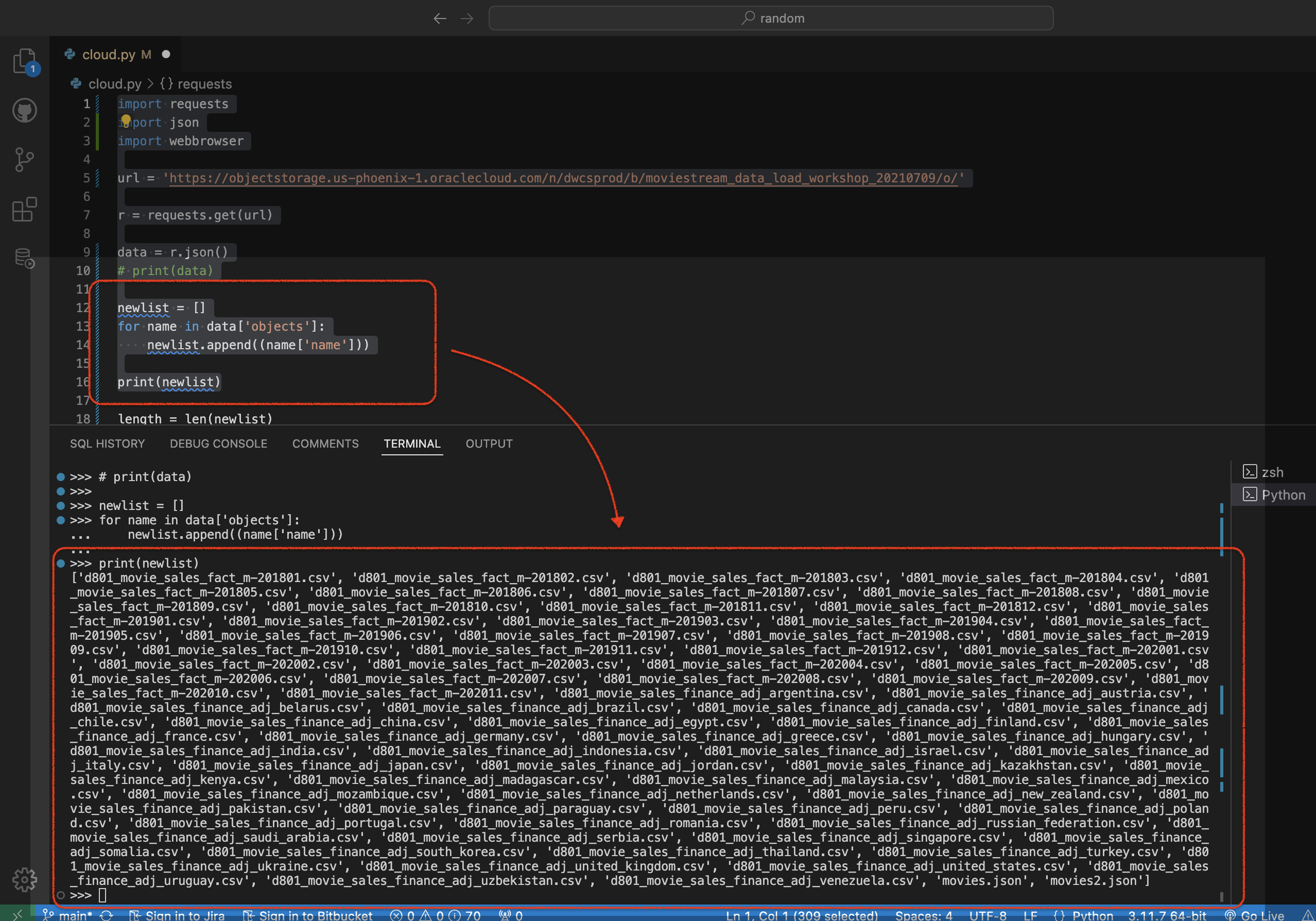
But how you ask? Good question, lots of trial and error. In short, I created an empty list, named newList. And later populated it with “stuff”. In normal people speak, lines 13-14 say the following,
“There is an item, actually many items in the JSON payload we received from our
GETrequest. For simplicity, lets call each of those itemsname, since ultimately what we want are file names. And we’ll use bracket notation to ‘drill’ down into more specific sections of the original JSON payload. And since we want just the file name (values), we want all the stuff that is inobjects(if that doesn’t make sense review the lines 1-10 section again). We are then going to add tonewListonly the names (aka values) of the files. And these lines of code are what help us to populate thenewListlist.
Maybe by this stage, you’ve caught on to what I’m trying to do. If not, I won’t spoil it for you 🙃.
Lines 18-19
And if you don’t quite “get it” yet, not to worry, it’ll click here in a second. Next, I need to see how many items are in this newlist I just created. Here is the code that is responsible for making that happen:
import requests
import json
import webbrowser
url = 'https://objectstorage.us-phoenix-1.oraclecloud.com/n/dwcsprod/b/moviestream_data_load_workshop_20210709/o/'
r = requests.get(url)
data = r.json()
# print(data)
newlist = []
for name in data['objects']:
newlist.append((name['name']))
# print(newlist)
length = len(newlist)
print(length)Here is the result in my terminal:
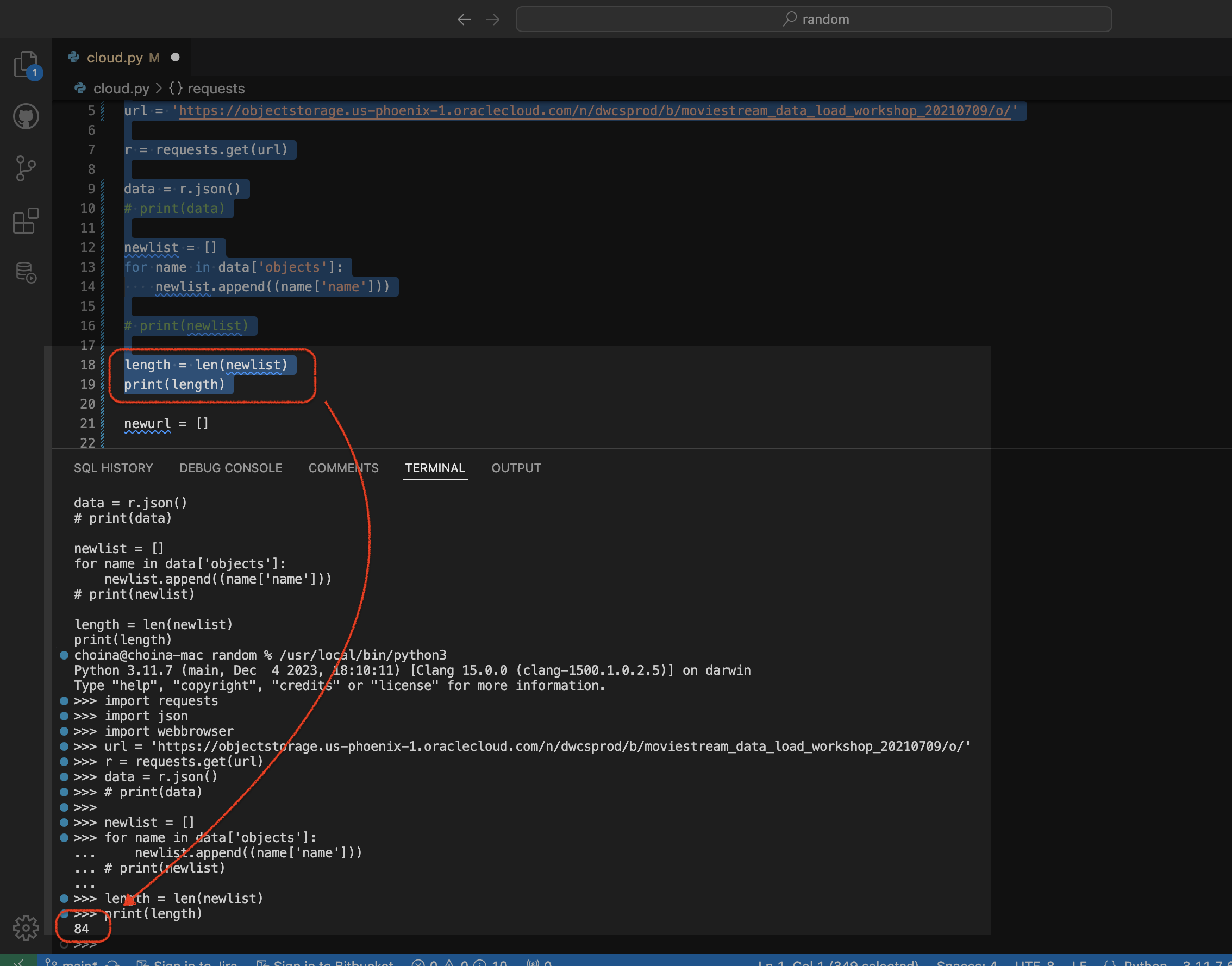
It looks like I have 85 elements, things, stuffs in my list. I’ll use that knowledge for the final steps in my script.
But why does that show as 84, and not as 85? Because Python uses zero-based numbering. So number 1 is actually number 0, and so forth and so on, etc...
Lines 21-26
import requests
import json
import webbrowser
url = 'https://objectstorage.us-phoenix-1.oraclecloud.com/n/dwcsprod/b/moviestream_data_load_workshop_20210709/o/'
r = requests.get(url)
data = r.json()
# print(data)
newlist = []
for name in data['objects']:
newlist.append((name['name']))
# print(newlist)
length = len(newlist)
# print(length)
newurl = []
for i in range(length):
newurl = url + newlist[i]
webbrowser.open(newurl, new=0, autoraise=True)
print(newurl)Line 21, you’ve seen this before (like 2 mins ago).
However, lines 23-25 are new. If you recall my “considerations and limitations” section. I bet there is a better way to do this (or all of this actually), but this worked for me, so I’ll keep it. In short, we know we have 85 “iterables” (that’s the for i seen in line 23) and the range(length) portion simply says, “Begin at 0 and then keep going till you reach the entire length of…length()…which in this case is 85).”
Next, I take the original URL (from line 5 in the code) and add each element of the newList to the end, making a newurl. From there, we open a web browser (new tabs actually) and visit that new amended URL aka newurl (I think more appropriately this is a URI, no?).
And for the visual, a video of the entire process (no audio):
And finally, for my own gratification, I’ll print out the newurl list just so I can marvel at my work. The new URLs:
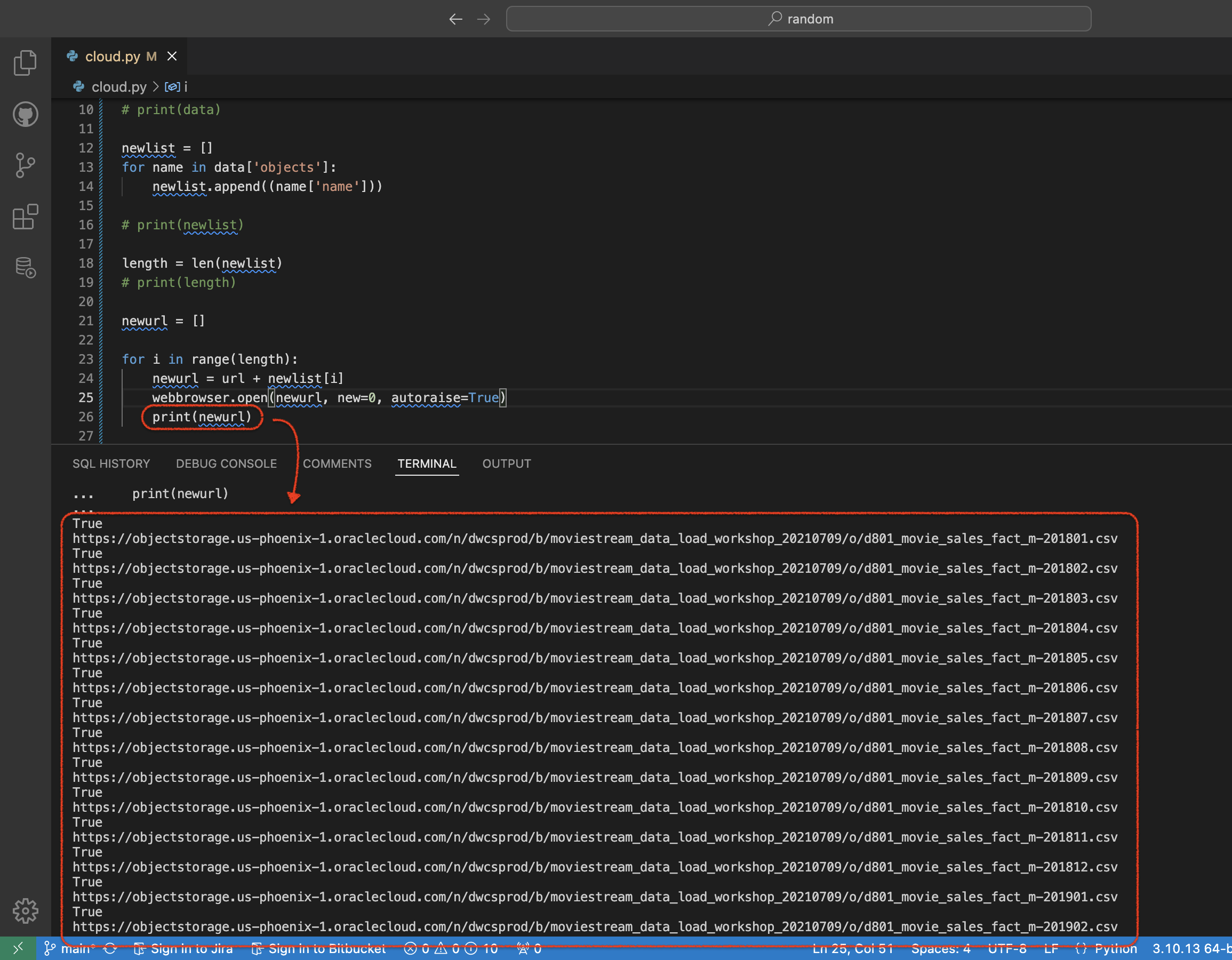
Now that I have these individual files, I can simply drag and drop them into my tables (in Database Actions obviously).
As always, this and other code can be found in my blog repo. I hope this comes in handy someday! That’s all for now 😀!
Follow
And don’t forget to follow, like, subscribe, share, taunt, troll, or stalk me!
Leave a Reply