Category: Python
-
From one API to another: Using ORDS Auto-REST to update a table
I think in this new age of AI/LLMs it is important to understand prompting. Eventually, whether we like it or not, we’ll all need to become “prompt engineers.” And as you’ll see in that thread, you actually have to know what you are doing to be able to ask the right questions and to challenge…
Written by

-
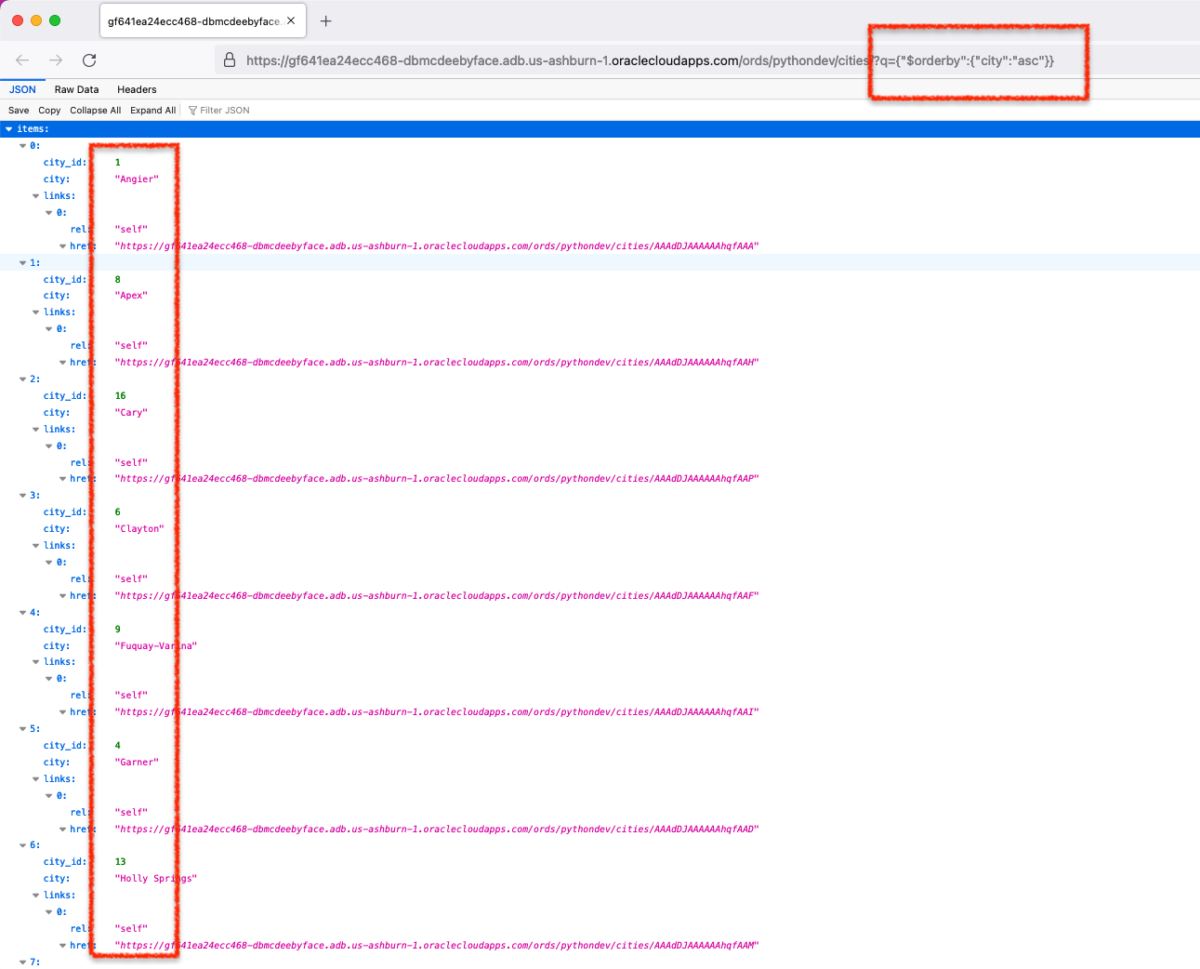
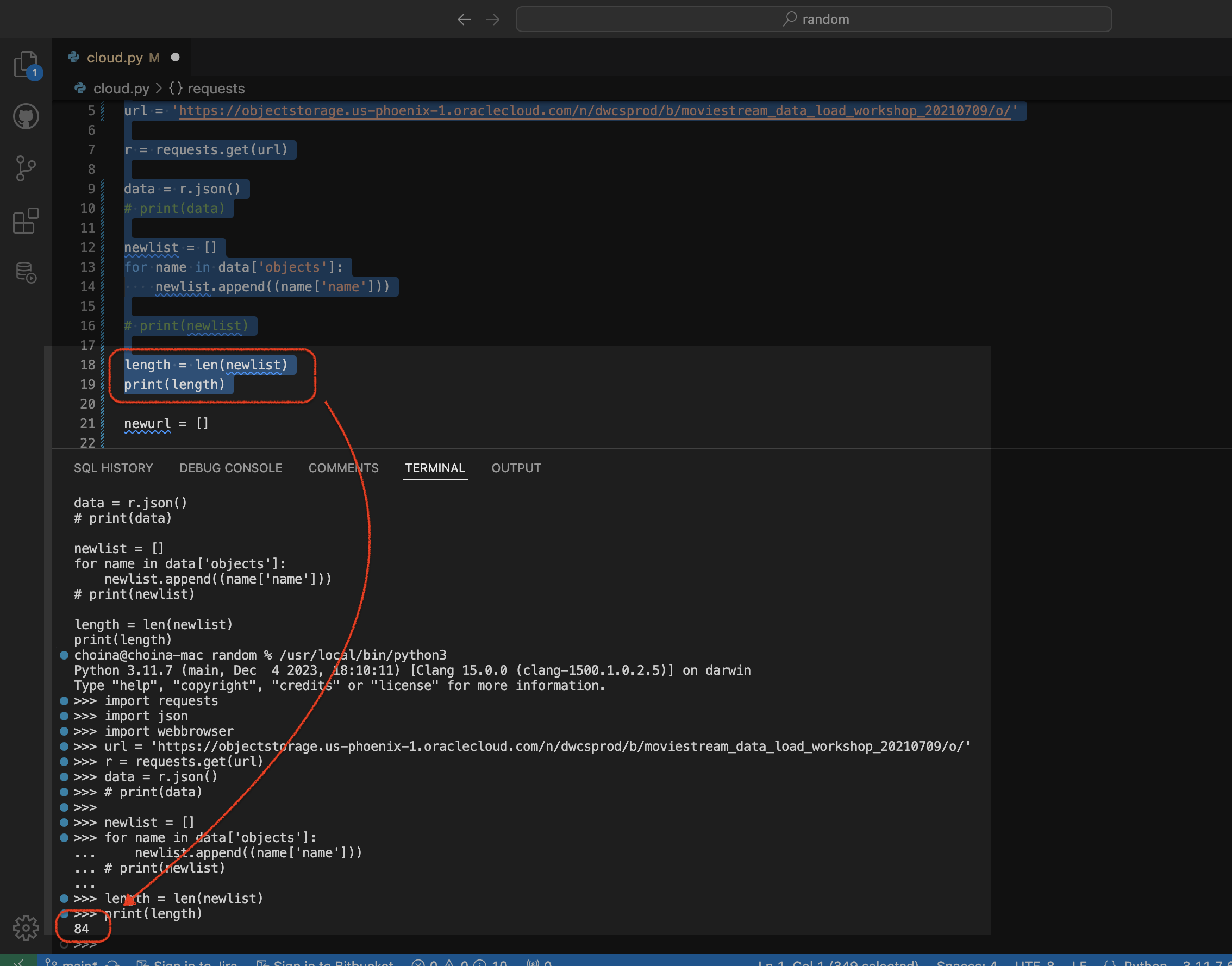
Python script to retrieve objects from Oracle Cloud Bucket
For…reasons, I needed a way to retrieve all the .CSV files in a regional bucket in Oracle Cloud Object Storage, located at this address: https://objectstorage.us-phoenix-1.oraclecloud.com/n/dwcsprod/b/moviestream_data_load_workshop_20210709/o You can visit it; we use it for one of our LiveLabs (this one), so I’m sure it will stay live for a while 😘. Once there, you’ll see all…
Written by
-
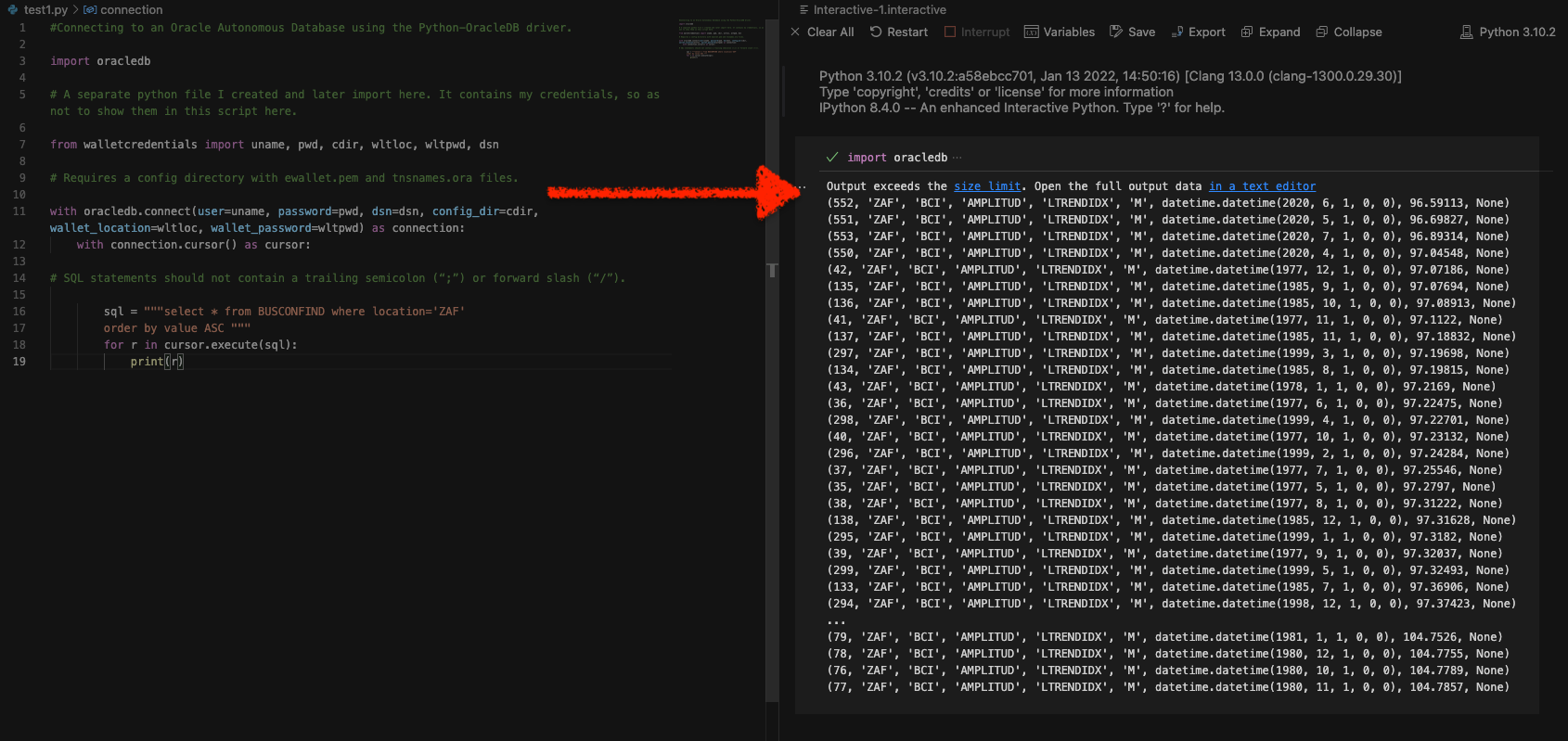
Python and the Oracle Autonomous Database: Three Ways to Connect
Watch the deep dive videos: Part I Part II Part III Welcome back I finally had a break in my PM duties to share a small afternoon project [I started a few weeks ago]. I challenged myself to a brief Python coding exercise. I wanted to develop some code that allowed me to connect to…
Written by
-
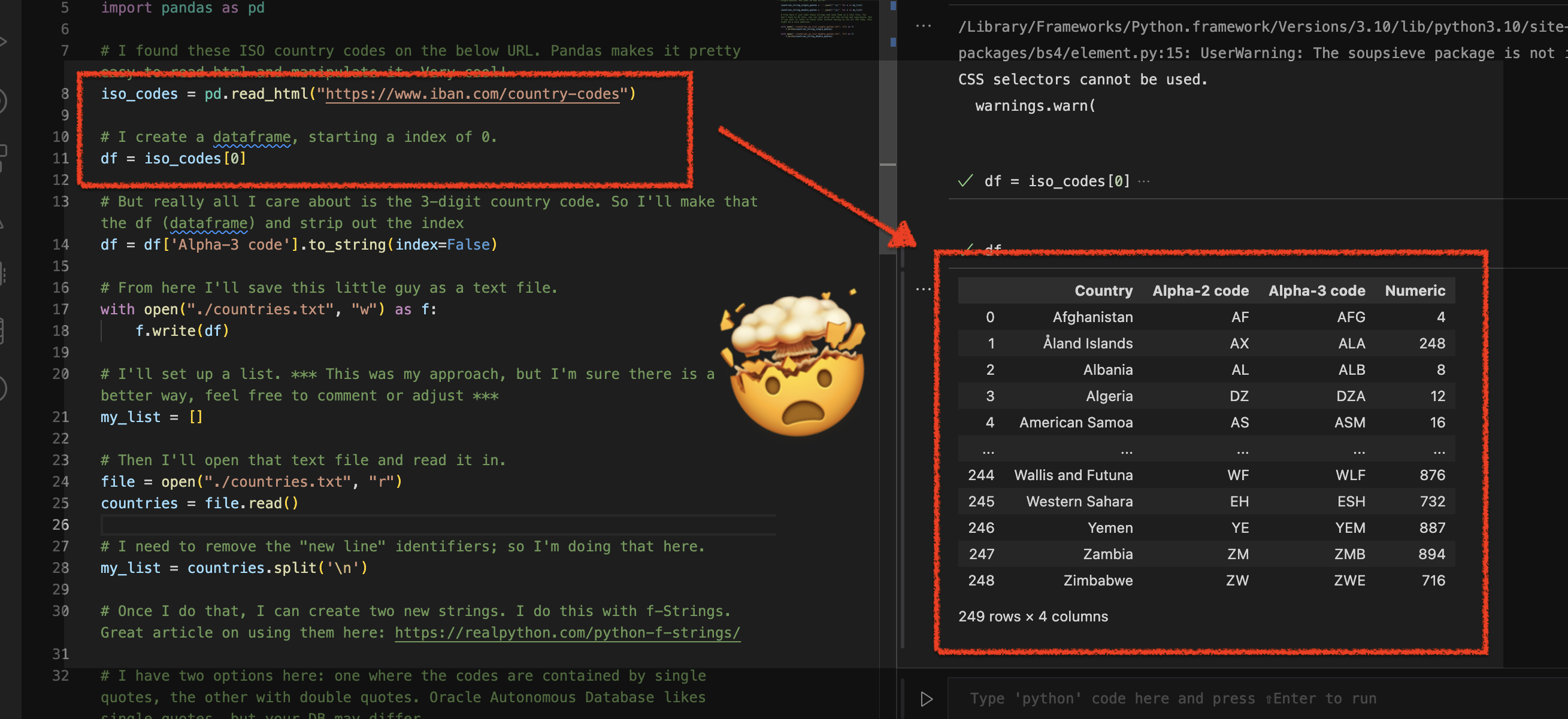
Using Python Pandas to turn ISO Country Codes into a string to use as values for a SQL Query
Summary, code, resources Problem While querying a table (based on this dataset) with SQL, you realize one of your columns uses 3-character ISO Country Codes. However, some of these 3-character codes aren’t countries but geographical regions or groups of countries, in addition to the actual country codes. How can you filter out rows so you are left…
Written by
-
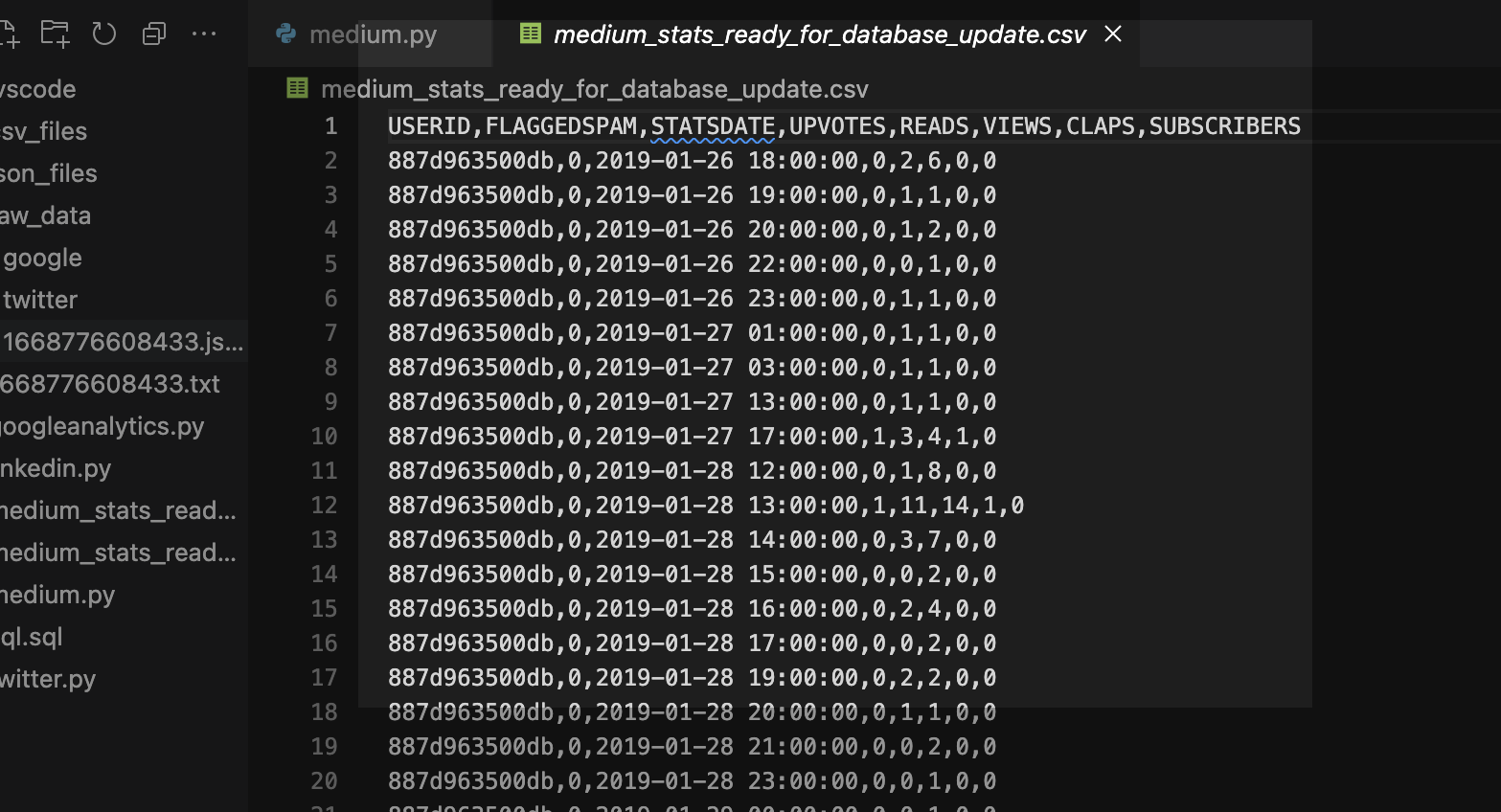
More fun with Medium story stats, JSON, Python, Pandas, and Oracle SQL Developer Web
That’s right; I’m back again for yet another installment of this ongoing series dedicated to working with Medium.com story stats. I first introduced this topic in a previous post. Maybe you saw it. If not, you can find it here. Recap My end goal was to gather all story stats from my Medium account and…
Written by
-
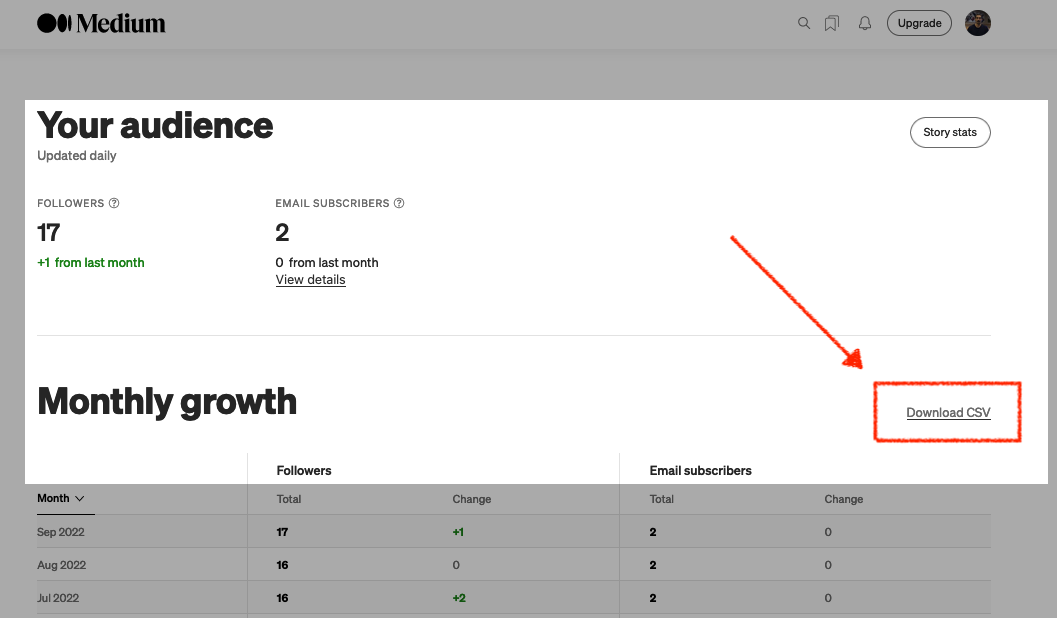
Fun with Python GET requests, Medium stats, and the Oracle Autonomous Database
I feel so silly for posting this because you’ll quickly realize that I will have to leave things unfinished for now. But I was so excited that I got something to work, that I had to share! If you’ve been following along, you know you can always find me here. But I do try my best…
Written by
-
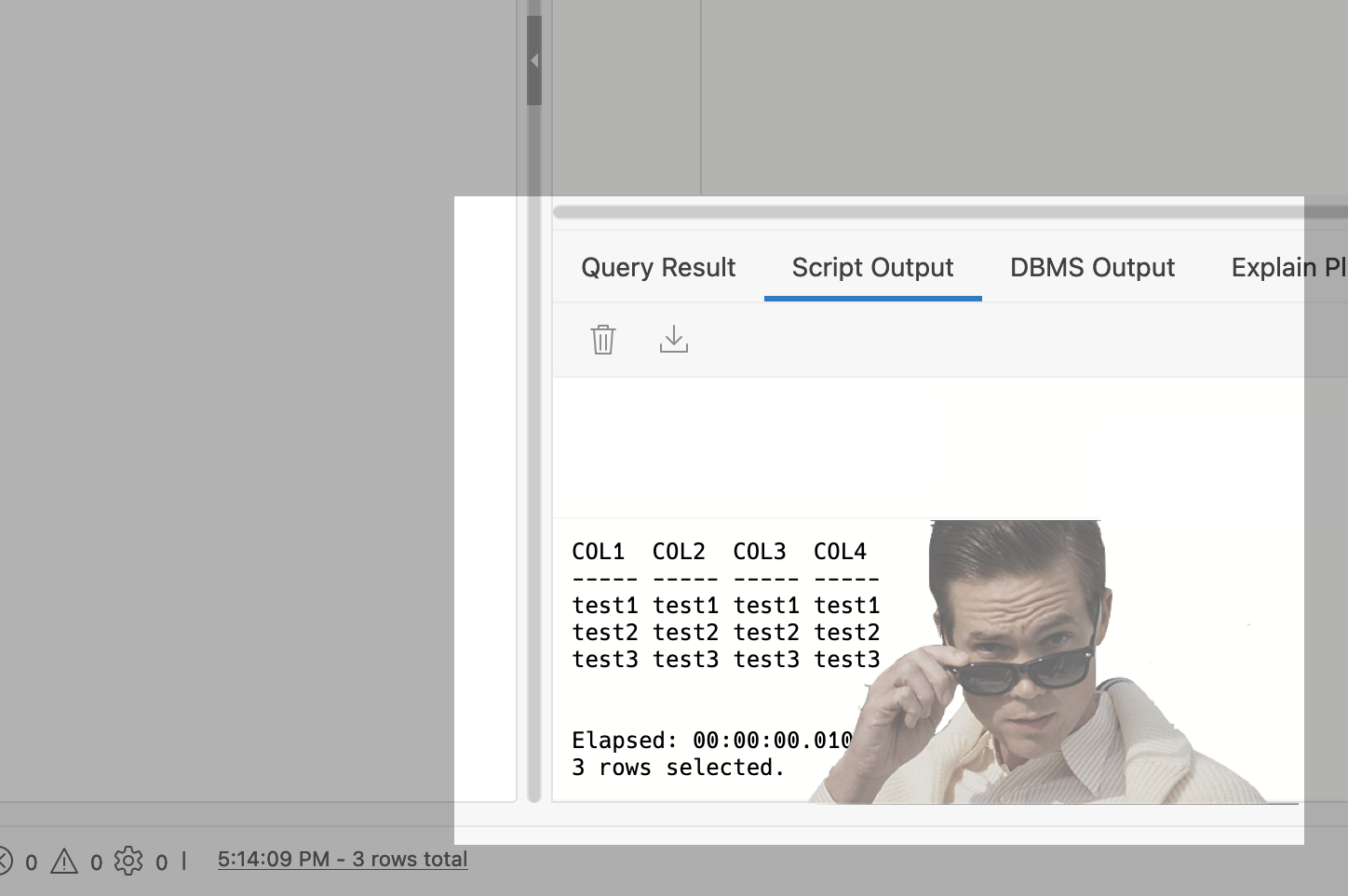
Python POST requests three ways with Oracle REST Data Services (ORDS)
The simple POST request It was bugging me that I couldn’t perform a simple Python POST request to an ORDS REST-enabled table. I don’t mean to convey that this isn’t possible. Up until very recently, I wasn’t able to do this. Luckily I had a few hours free, so I took to the docs to…
Written by
-
Flask, Python, ORDS, and Oracle CloudWorld 2022
Python, Flask, and ORDS Restaurants Web Application update If you’ve been following along, then you are probably aware of the python/flask/ORDS journey that I’ve embarked on. If not, you can read up on the overview here. The idea was to take local restaurant health inspection scores (aka Sanitary grades) and present the data to a…
Written by

-
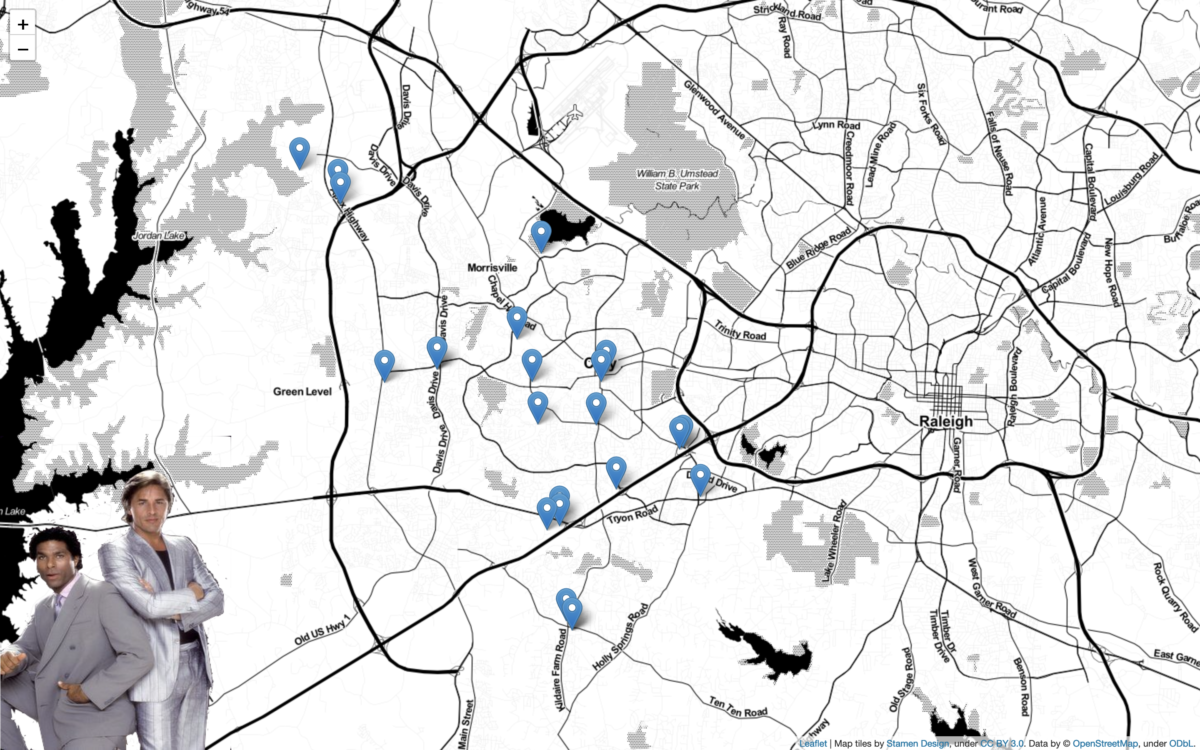
Python + Folium + Oracle REST APIs (aka ORDS)
Willkommen I stumbled upon a new [to me] python library called Folium. It’s a mapping tool that enables python developers (or is it programmers, which is less offensive?) to visualize data on a Leaflet map. About folium Folium makes it easy to visualize data that’s been manipulated in Python on an interactive leaflet map. It…
Written by