
Let us begin
I log into Database Actions as my newly created “Python Developer” and navigate directly to the “Data Load” page (found under the Data Tools section of the Launchpad). I choose to “Load Data” from a “Local File.” I click “next,” click the pencil icon (see the arrow in the image), and navigate to the “File” tab. I scroll to the “RESTAURANTOPENDATE” column and see this:
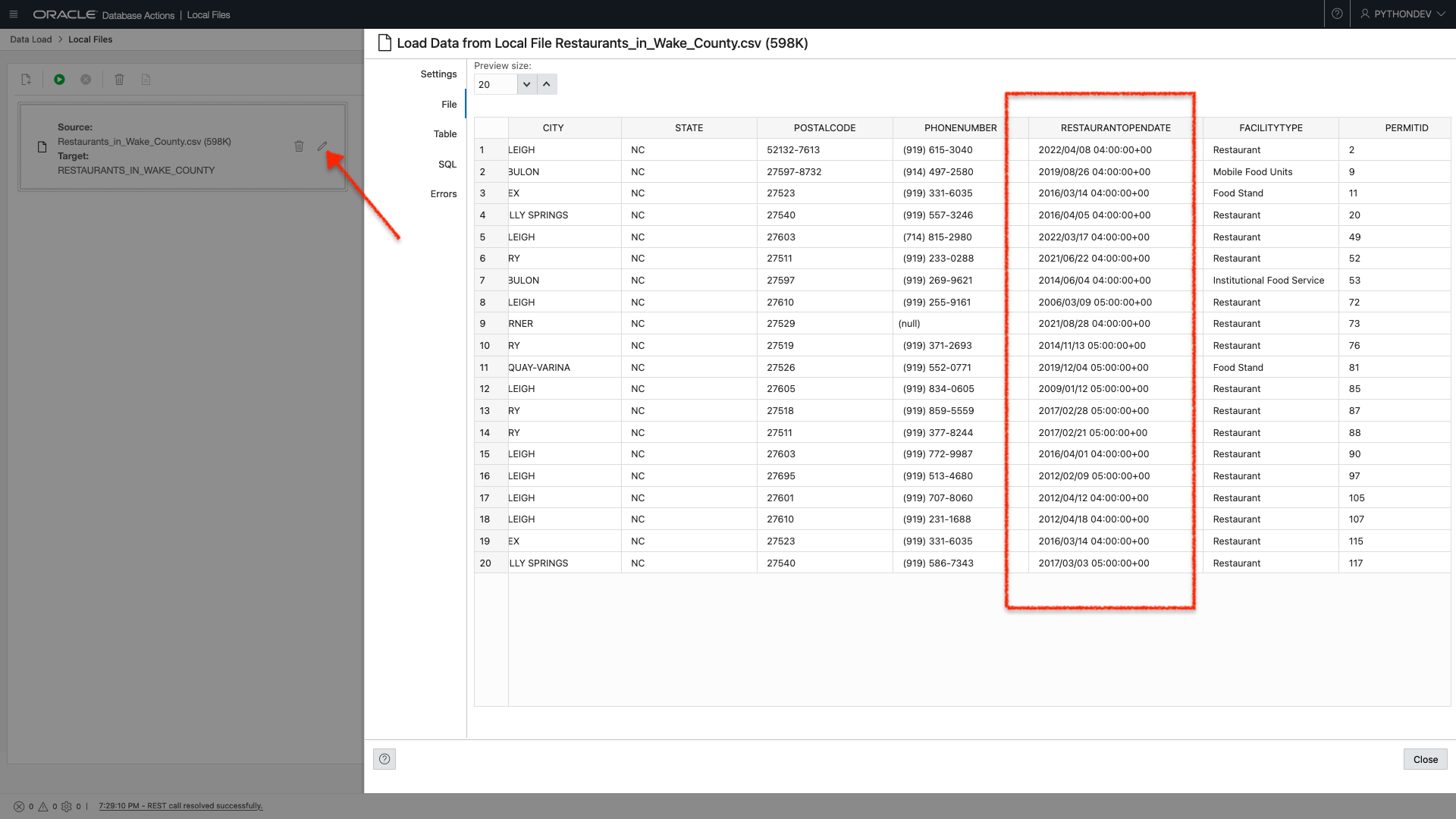
In a previous post (if you’re new, you can read the end-to-end process), I discussed how this time (“04:00:00+00” or “05:00:00+00”) wasn’t necessary for me. At that time, I used the “Find and Replace” function in Excel (I’m sure you can do the same with Numbers, Sheets, or Calc) to replace all occurrences of time with “” (i.e., nothing).
But in the spirit of doing things in five days, when they could have taken but five minutes, I opted to see if I could achieve a similar result in python.
Goal
Create a python script that will allow you to remove part of a value in a .CSV file.
WARNING: I thought this would be a simple task. I should have known better. My approach may not be ideal for your situation, but hopefully you’ll learn something. Or at the very least maybe you can bookmark this post, along with the resources (at the end of the post) I'm including for later use.
Regular Expressions
I am confident there is a way to achieve this goal with the .CSV library in python. There is probably a way to do this with python out of the box. I couldn’t figure it out.
I’m also reasonably confident that my approach is on the verge of ridiculous. Nevertheless, Regular Expressions, and the Pandas library, in python are what worked for me.
What are Regular Expressions?
Good question. I still don’t know, but here is what I found on Wikipedia:
“A regular expression (shortened as regex or regexp; also referred to as rational expression) is a sequence of characters that specifies a search pattern in text. Usually, such patterns are used by string-searching algorithms for “find” or “find and replace” operations on strings, or for input validation. It is a technique developed in theoretical computer science and formal language theory.”
That is so painful to read, but the way I understand it is that we use Regular Expressions in pattern-matching. Essentially you create a pattern and then tell your application (or script) to search for it. From there, you can include more code to perform more actions. In my case, those actions would be to find a pattern and replace that pattern with nothing.
So what is the pattern?
One of the benefits of having zero formal training in application development (in this case, computer science and formal language theory) is that occasionally, you might take an approach that, while unintuitive, works well enough.
And after many, many hours of trial and error, parsing through Stack Overflow, reviewing hours of YouTube, reading pages of blogs, and occasional use of the “I’m Feeling Lucky” button on Google, it occurred to me that my pattern was:
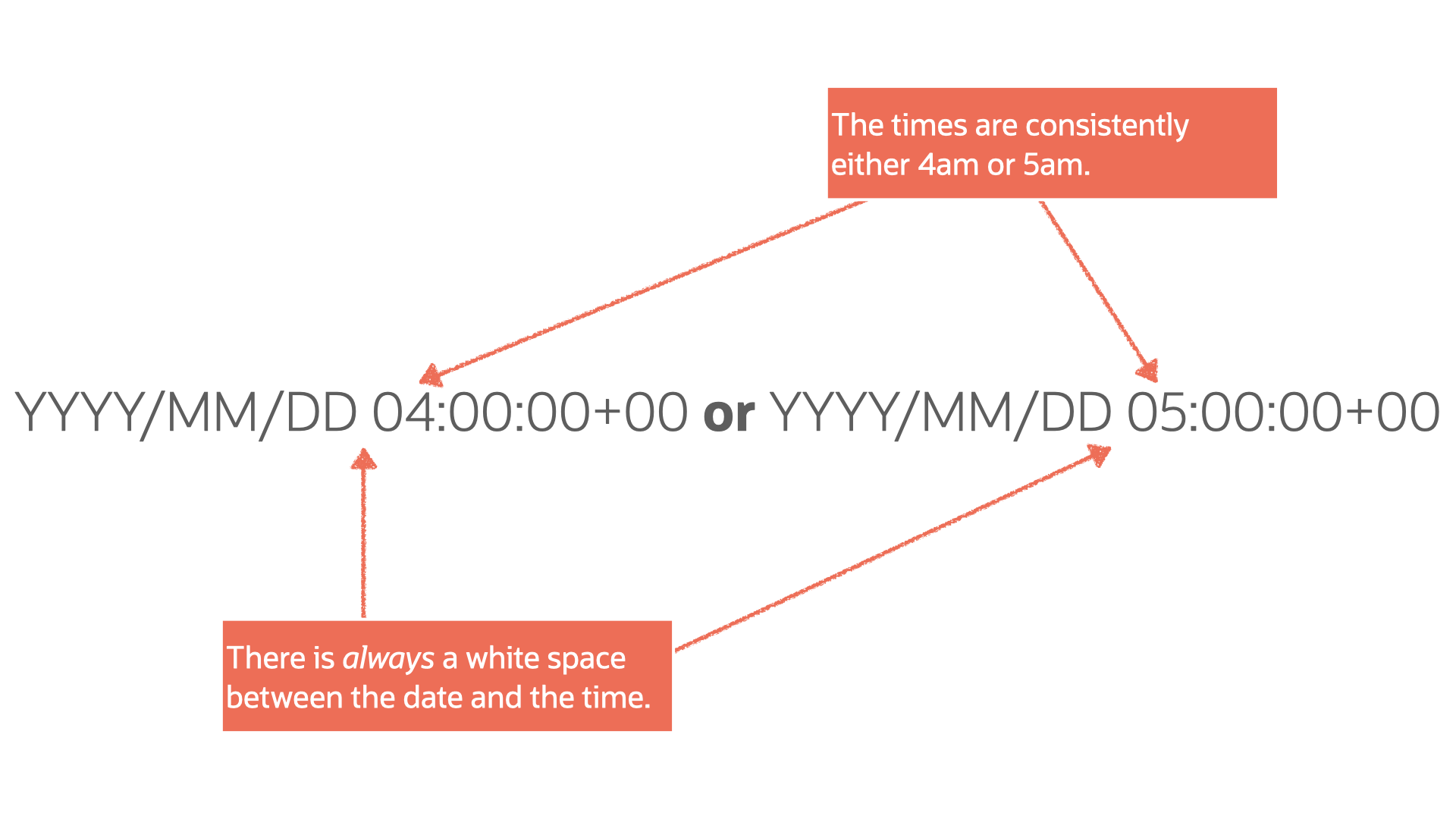
After reviewing more documentation and other various resources (I have an entire section at the end), I more clearly identified a pattern:
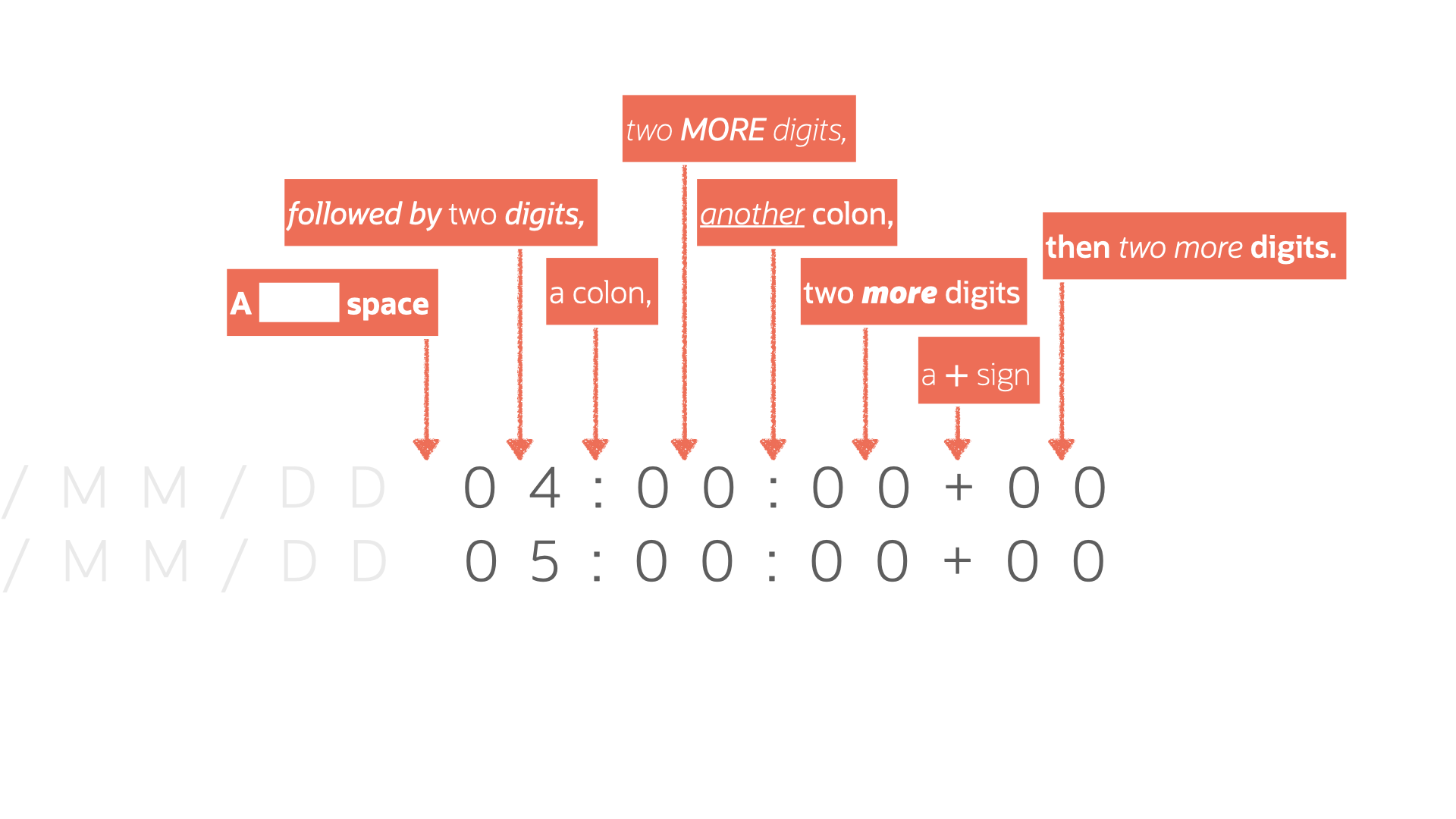
Coming up with a clearly-defined pattern helped inform me as to how I could create the following Regular Expression:
'\s\d+:\d+:\d+[^a-c6]\d+$'I then did some more stuff, and that was it! Follow me for more…
I’m kidding.
Deep Dive
I can’t teach you everything, because I’m probably only ahead of you by a week at this point. But I can explain, in the hopes that it will make sense. Let me continue with the above Regular Expression (again, you’ll want to spend some time in the resources section I’ve included to understand better how this all fits together).
But the above Regular Expression can be defined like this:
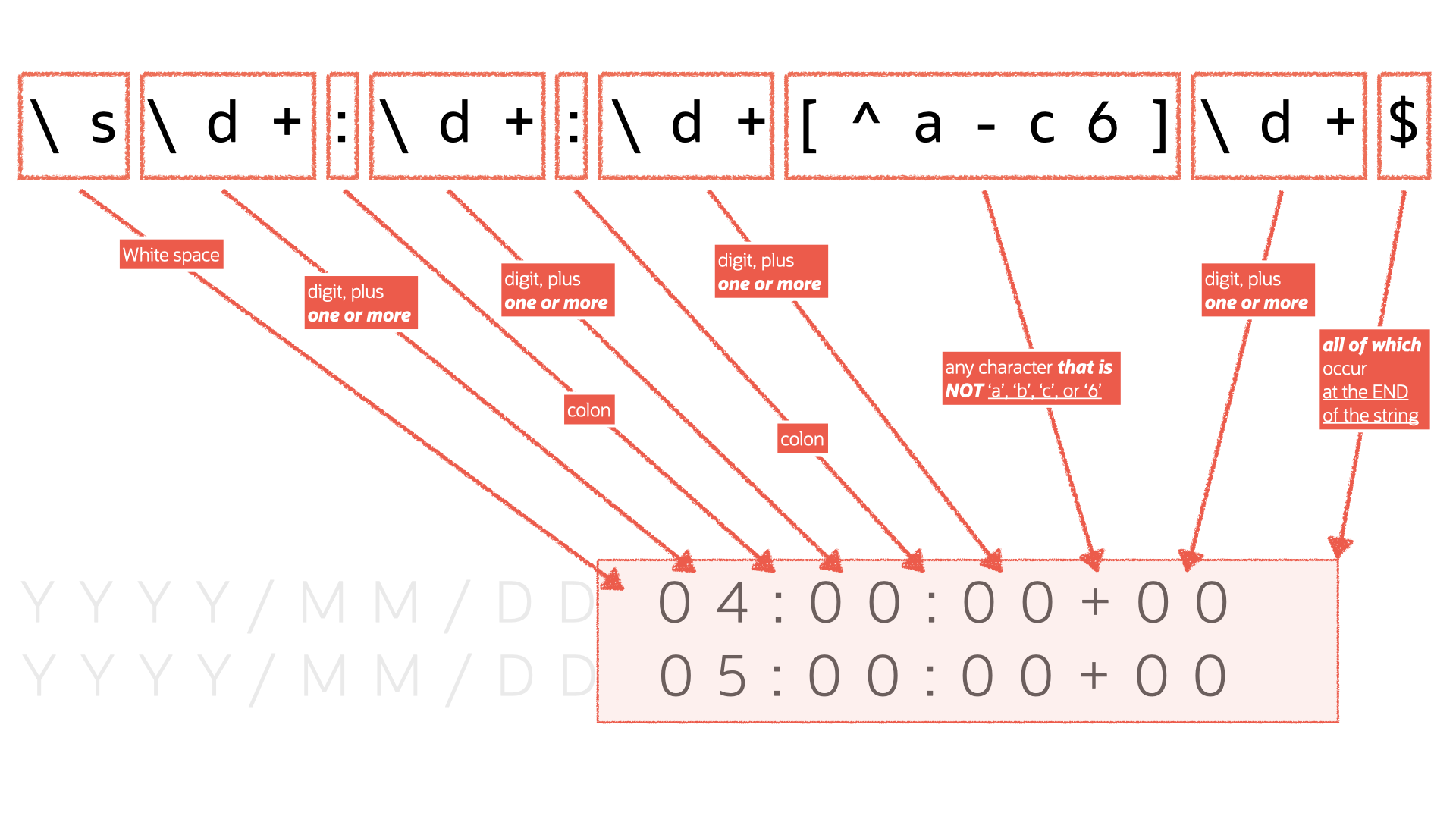
I then took the above and plugged it into this nine (12 with sections, slightly more with comments) line script:
from pickle import NONE, TRUE
#This doesn't seem work without pickle, still not sure why
import pandas as pd
#You need this to do anything related to dataframes (i.e. "df");
# if you're a data scientist and you use python, you may already
# be familiar with this
import re
#You need this for Regular Expressions to work
d = '/Users/choina/Documents/untitled folder/Restaurants_in_Wake_County.csv'
#I'm assigning the file to "d"
df = pd.read_csv(d)
#df means dataframe. Here I'm telling panda to read the .CSV file
# that I just created ("d"), and consider that the "dataframe".
print(df.dtypes)
#This is optional, but when I do this I can see what the various
# datatypes are (according to pandas). The RESTAURANTOPENDATE column
# is an 'object'.
for RESTAURANTOPENDATE in df:
df['RESTAURANTOPENDATE'] = df['RESTAURANTOPENDATE'].str.replace('\s\d+:\d+:\d+[^a-c6]\d+$', '', regex=TRUE)
#This is a "For Loop" that says set the RESTAURANTOPENDATE column
# contents equal to the following: FIRST, consider the values in the
# column as string and replace the contents using this process:
# find a pattern that matches this Regular Expression, replace
# it with NOTHING, then take that column,along with the other
# columns and...
df.to_csv('newrest.csv')
#Save it to a new .CSV file called "newrest.csv"Code as an image for reference:
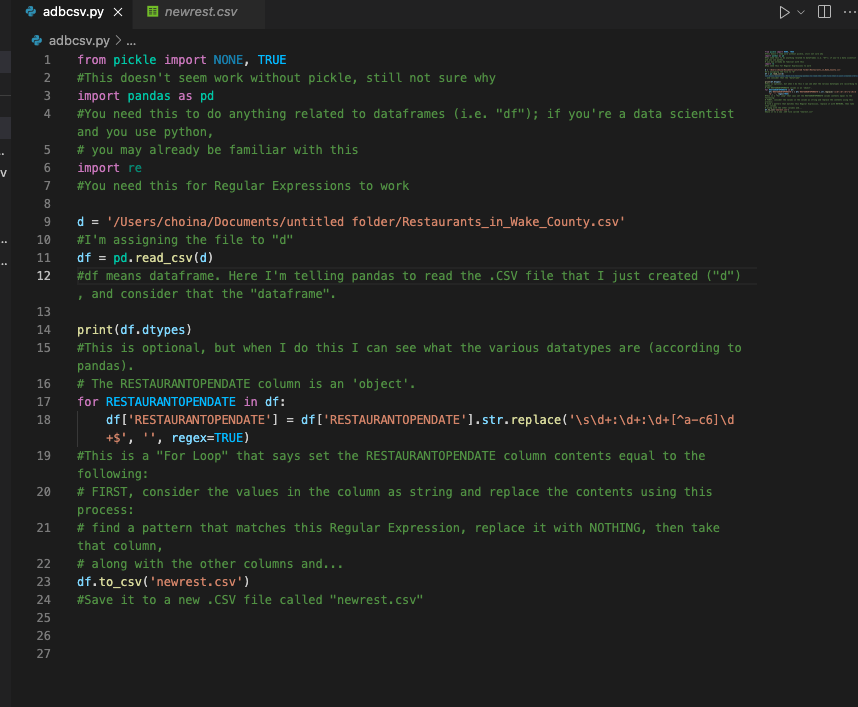
In short, (I’ve left detailed comments for reference), these nine lines of code search for a pattern and replace it with nothing when found. We then take these results (including the rest of the .CSV file) and save them to a new file called “newrest.csv.”
Please, reference this script. Tweak it as needed. Or drop me a note if you need an outside perspective. Good luck!
One more thing
Pickle, Pandas, and RE are all required for this script to work.
Note: While I understand Pickle is a library that deals with the serialization of objects in python. I've no idea what that means, and reading about it makes my brain melt. Additionally, I’m not sure if this is expected behavior, but when I ran an earlier version of this script, this "Pickles" library just appeared at the very top. If this has happened to you, please leave a comment, because I'm scared there may be an actual ghost in my machine.
Moving on
The rest is pretty straightforward.
I then went back into Database Actions (it had been so long that I’d expected a new version had been released already), loaded my data, and inspected the column in question:
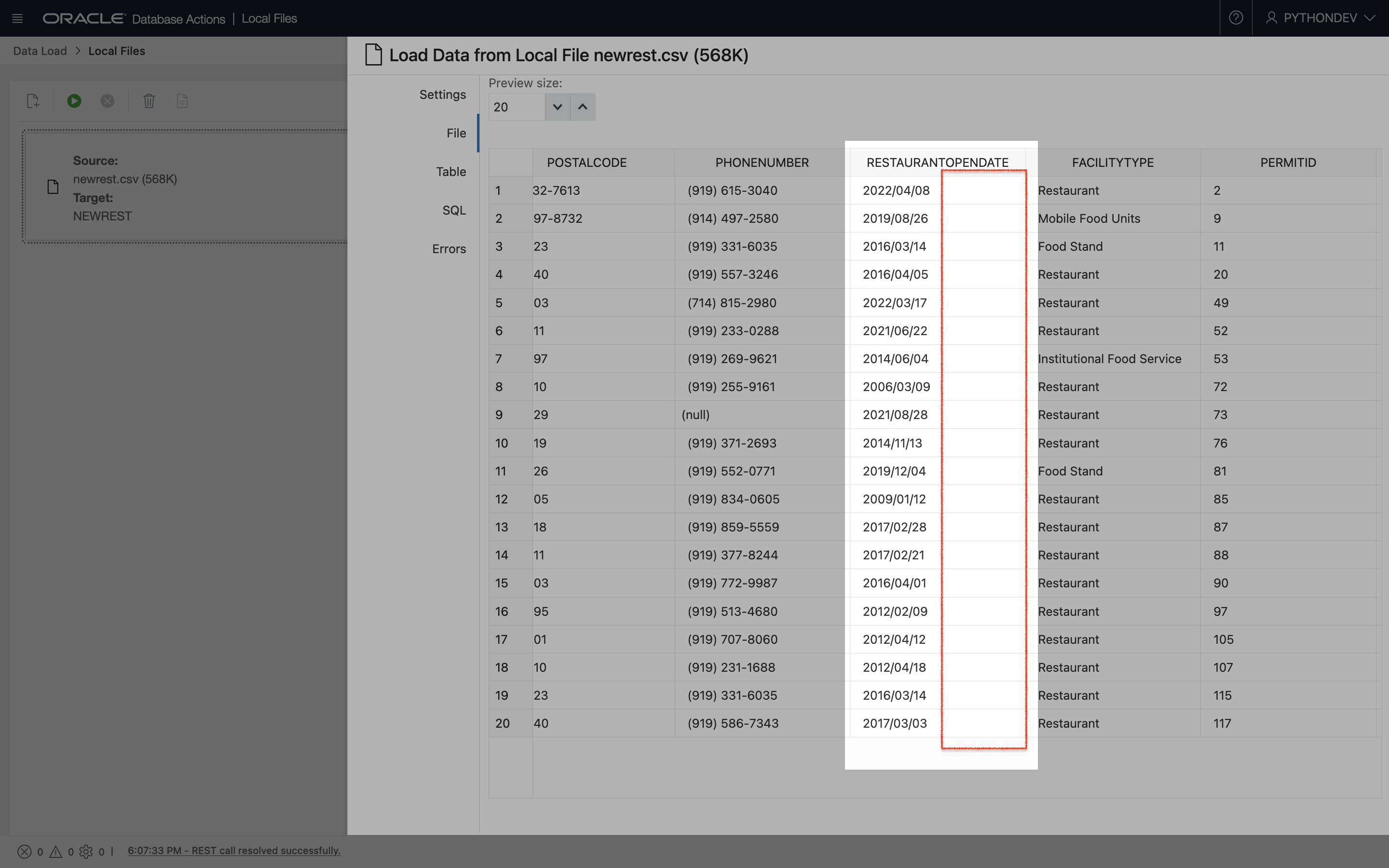
Looks good to me!
Magic
Something I noticed was that my Autonomous Database automatically recognizes the “RESTAURANTOPENDATE” column as a data type of “Date.” I didn’t have to do anything special here, and I thought this was pretty cool. Take a look:
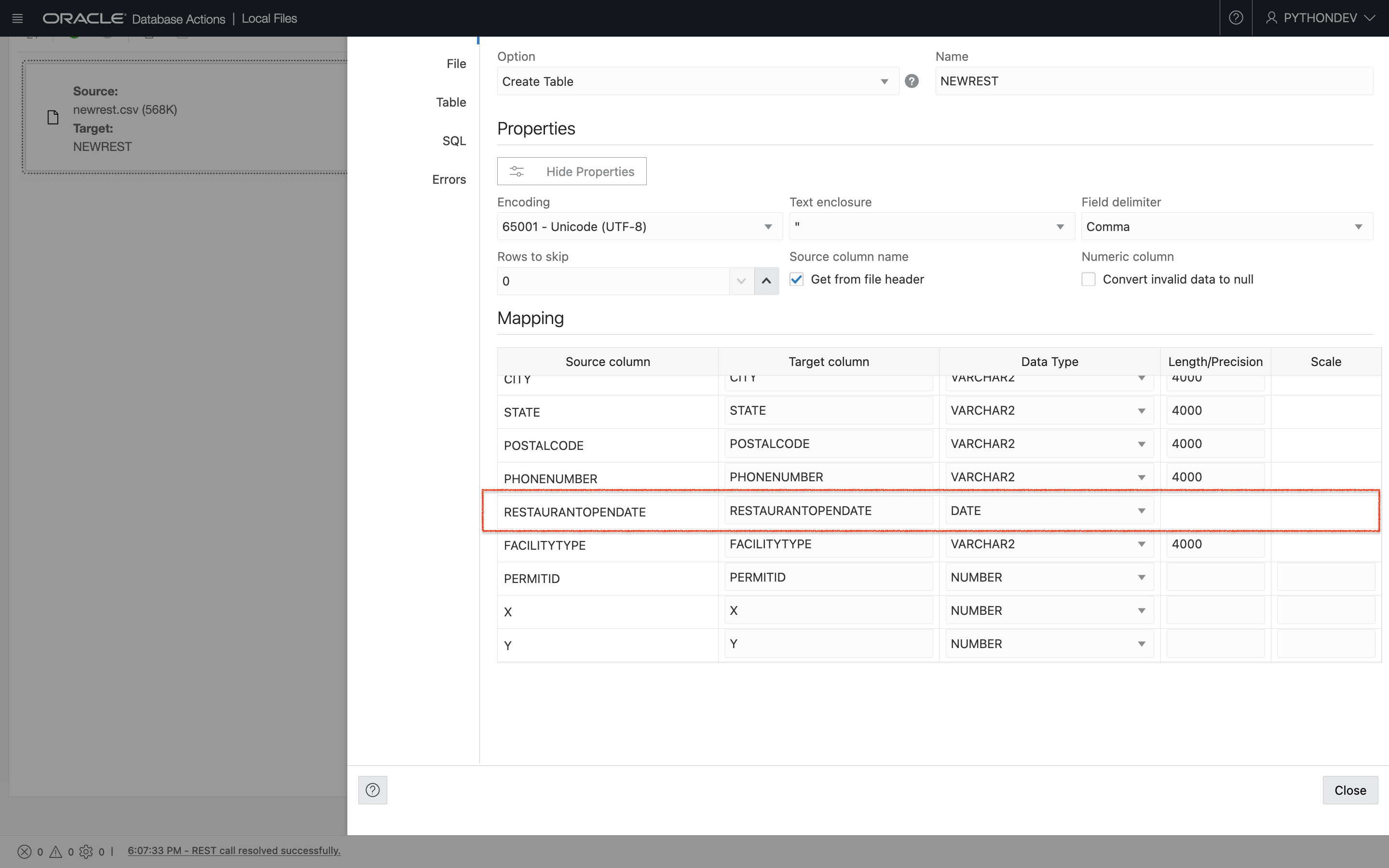
Addendum to the addendum
Once imported, you can also use Regular Expressions in your database (with SQL). But if you’d like to clean your data before it reaches your ADB, the approach I’m writing about here is also a great option!
Resources
As promised, here are all the resources I’ve curated that might assist you should you choose to take the road less traveled…
- Important/relevant documentation:
- Pickle
- Regular Expressions
- Pandas
- Related to this post, there are specific pages that were a huge help. Specifically:
- Remove a suffix in a string
- Replace a string in a series
- lstrip (remove leading characters) a string
- strip (remove leading and trailing characters) a string
- Discover/better understand your dataframe’s attributes and characteristics
- Iteration in Pandas
- Replace values in a series (aka column in Pandas)
- Related to this post, there are specific pages that were a huge help. Specifically:
- Stack Oveflow – this is a series of “bookmarked” questions about Python and Regular Expressions, that helped me. They might be of use. They aren’t intended to teach you, but rather aide you in gaining a better perspective.
- YouTube – a playlist I created that might be worth reviewing (at a minimum watch Case Digital’s “How to Remove Characters From a Pandas Dataframe In Python” video).
- Regular Expression Editors:
- Pythex (make sure you click the “Regular expression cheatsheet” button to expand/see a valuable quick reference – also, apparently a more complete version can be found here)
- Regular Expressions 101 – this includes an enormous library of previously created Regular Expressions. There is a “debugger” too!
An even simpler solution
I discovered an even simpler solution to this problem. As I was reviewing the Pandas documentation I noticed there was functionality built directly into Pandas. This can be done with the “datatime” function.
And you can take it one step further with what is referred to as a “.dt accessor.” (you’ll see this in the updated code I’m including). This accessor allows you to manipulate a Series (aka a column) within a Pandas dataframe (df).
There are quite a few time-date properties you can manipulate in Pandas, all of which can be found here. The “Time Zone Operations” section is where the “.dt accessor”, is briefly mentioned. For more context, I’d recommend reviewing this section on the .dt accessor and how they interplay with a Pandas Series.
Don’t stop there though, the main python documentation discusses the basics of date and time operations. Without further ado, on to the new code:
import pandas as pd
import numpy as np
#You don't have to do it like this. You could have a single "d" and then just comment/uncomment each line as needed.
d1 = '/Users/choina/Downloads/Food_Inspections.csv'
d2 = '/Users/choina/Downloads/Food_Inspection_Violations copy.csv'
d3 = '/Users/choina/Downloads/Restaurants_in_Wake_County copy.csv'
#The same thing here, you could just have a single "d" and then just comment out the other two, when not needed.
df_1 = pd.read_csv(d1)
df_2 = pd.read_csv(d2)
df_3 = pd.read_csv(d3)
#Same goes for this too. This is either very slick of me, or incredibly lazy.
df_1['DATE_'] = pd.to_datetime(df_1['DATE_']).dt.date
df_2['INSPECTDATE'] = pd.to_datetime(df_2['INSPECTDATE']).dt.date
df_3['RESTAURANTOPENDATE'] = pd.to_datetime(df_3['RESTAURANTOPENDATE']).dt.date
#Same, same here as well. You could do one at a time. But it works, I double-checked my work.
df_1.to_csv('newninspect.csv')
df_2.to_csv('newviolate.csv')
df_3.to_csv('newrest.csv')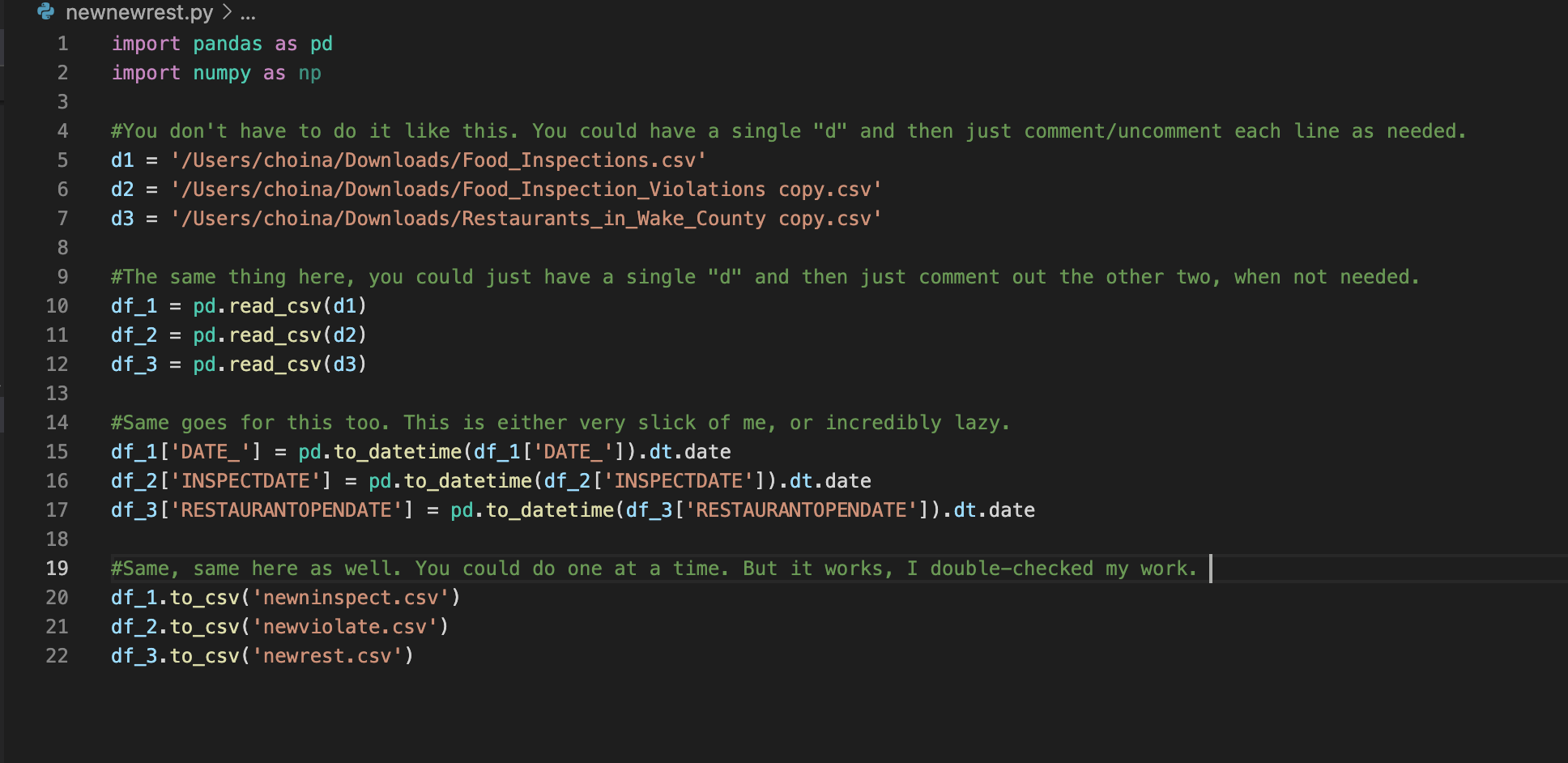
About the update
This code is certified fresh – meaning, it works. I triple-checked. The only thing I’ve noticed is that lines 12-14 must-have “.dt.date” at the end. From what I am reading (and am inferring from the documentation), it looks as though you need to first “treat” the Series with the “to_datatime” function. After that, the entire dataframe is in limbo (not quite written out to a new .CSV), waiting. Before the next step, we can strip the time portion out using the .dt accessor (i.e. the “.dt.date” portion located at the end of lines 12-14).
From there it is simply a matter of writing out these updated dataframes to the three new expectant .CSV files.
Find Me
Please come back for more. I’m going to be working on views in my Autonomous Database, and then later, I’ll REST-enable them with the help of ORDS!
Leave a Reply