Tag: Oracle Database
-
Troubleshooting: reviewing ORDS connections, your application server, and response times
Symptom/Issue In an internal Slack thread today, a user was trying to diagnose browser latency while attempting to connect to the ORDS landing page. Peter suggested what I thought was a pretty neat heuristic for checking connections to ORDS and your database, as well as latency. Methodology Let’s say your symptoms are either slow loading…
Written by

-
ORDS 24.4 Release Highlights
So what even is new in ORDS 24.4? How about an abbreviated list of some fan favorites? Pre-Authenticated endpoints Using the new ORDS_PAR PL/SQL package, users can create, revoke, issue and set tokens and token life for specific resources. Your REST-enabled schema will automatically have access to this new feature in 24.4. You can execute…
Written by
-
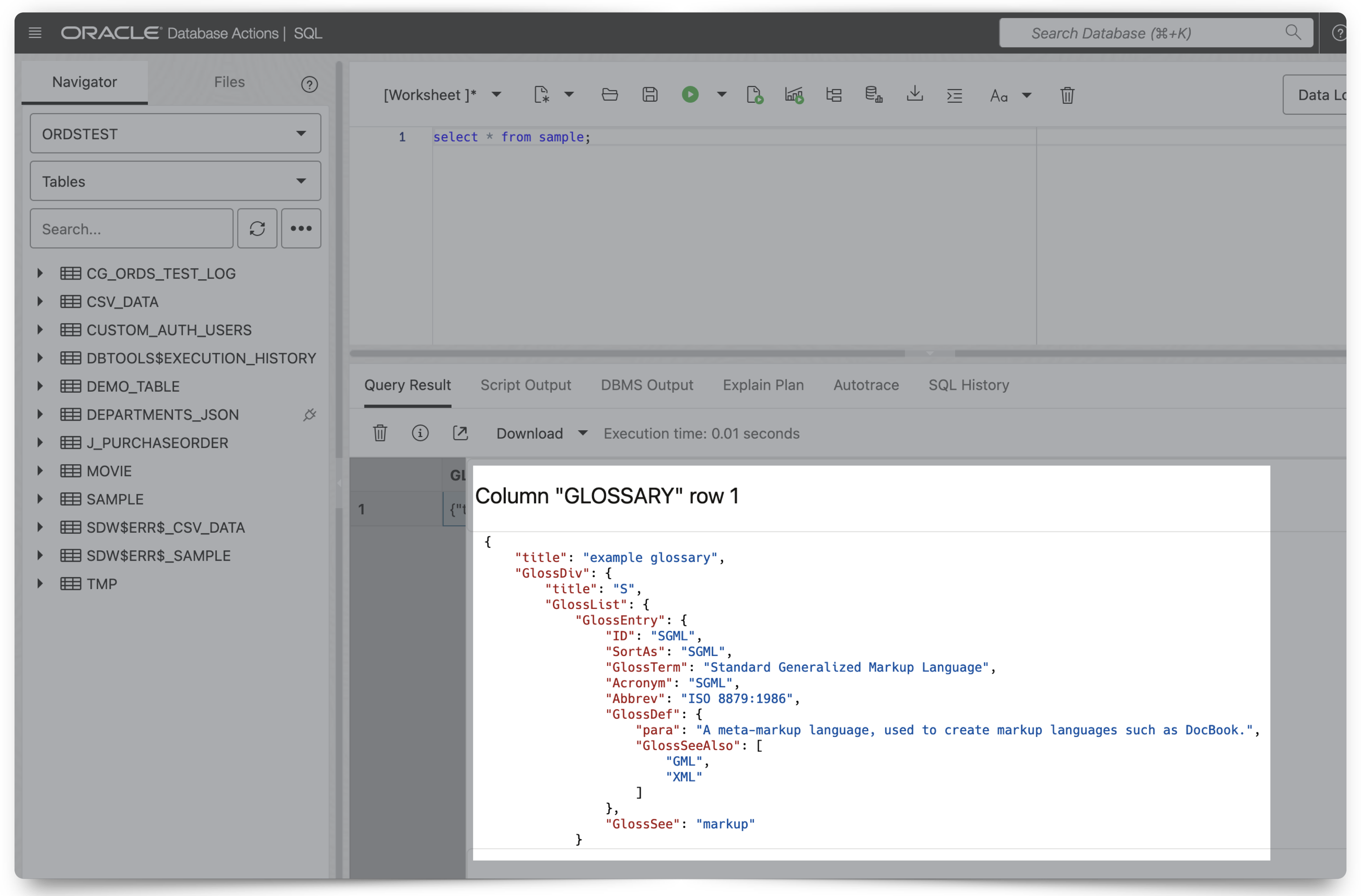
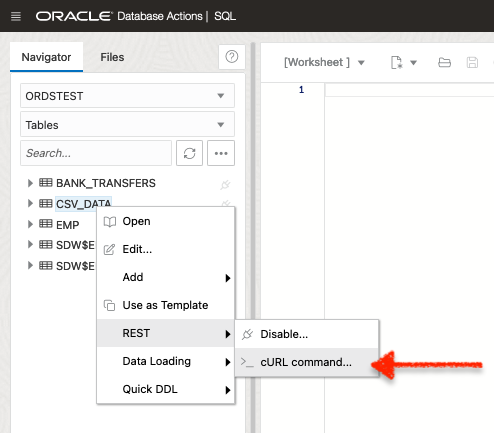
ETags and Oracle REST APIs
About this post I explore ETags and how they can be used in cURL commands when interacting with Oracle REST APIs. I also discuss some of the performance benefits of using ETags. This is not exhaustive, but I hope it introduces you to ETags or reminds you of their existence! But first… LATE-BREAKING NEWS!! A…
Written by
-
An intro to using Oracle SQLcl on Mac
Did you know you can use Homebrew to install Oracle’s SQLcl on Mac? I just realized this about a week ago (always the bridesmaid, never the bride…amirite??). Homebrew First you’ll need to install Homebrew (I’m sure there are other ways to install SQLcl, but installing through Homebrew was a breeze). You can install Homebrew on…
Written by
