Tag: podman machine
-
Podman container is unhealthy with Oracle database images
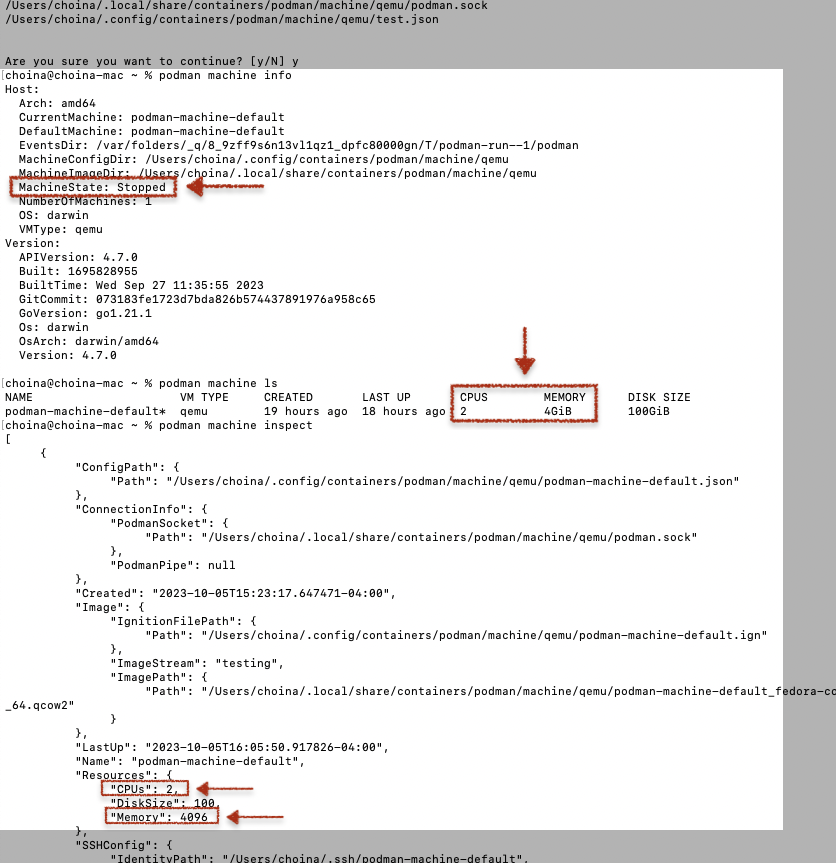
Problem Description You’re working with podman containers (maybe like me – the ones from the Oracle Container Registry), and when you execute the podman ps command, you see something like this in the standard output: In this case, I already had another container with an Oracle 21c database; that one was healthy. I previously wrote up a…
Written by