Next episode
With my Autonomous Database up and running,I needed to find some data to upload. After some quiet reflection, I decided upon three datasets that should be plenty fun.
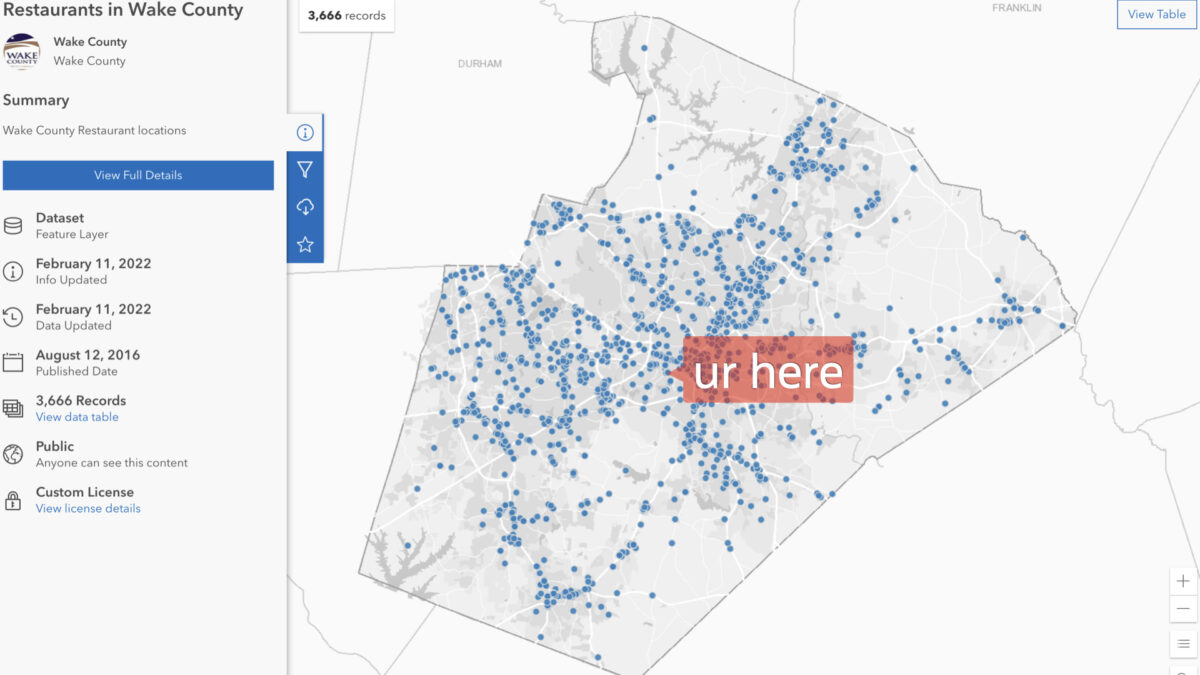
A bit of context; I currently live in Wake County, North Carolina. And it turns out that we’ve been very progressive with providing open, accessible data to our citizens. I really wanted to do something with food, so I was surprised when I found the following three datasets (among the nearly 300 available):
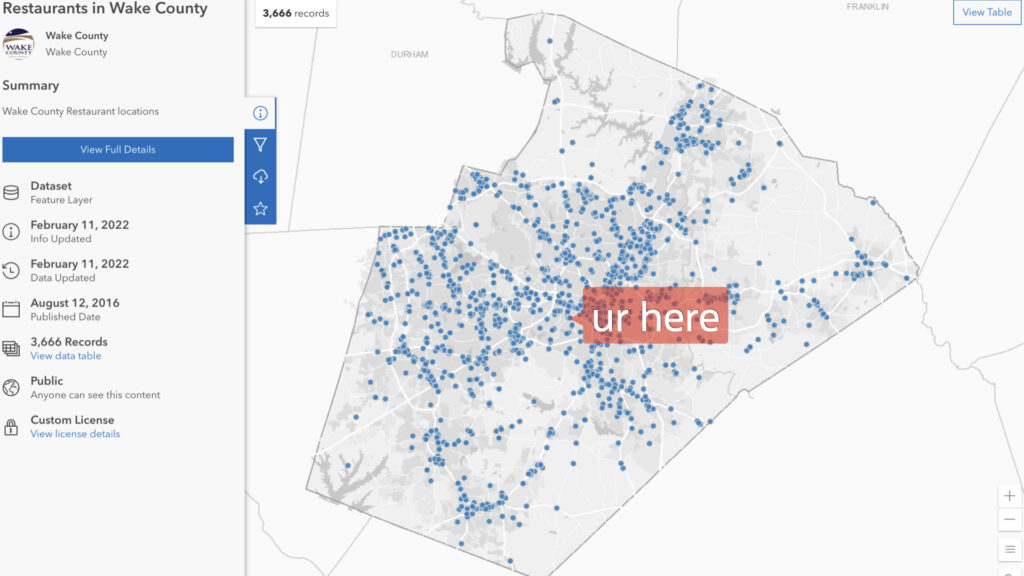
Always read the docs
Upon reading the documentation, I discovered that these datasets could be all connected through their HSISID* Permit ID fields. Which should come in handy later as it could make for some very interesting (if not amusing) revelations.
*I’m not sure of the acronym, but the documentation defines the HSISID as a, “State code identifying the restaurant (also the primary key to identify the restaurant).”
To the data loading
I’m sticking with the Oracle Database Actions* web-based interface for now.
*Oracle Database Actions was previously known as Oracle SQL Developer Web.
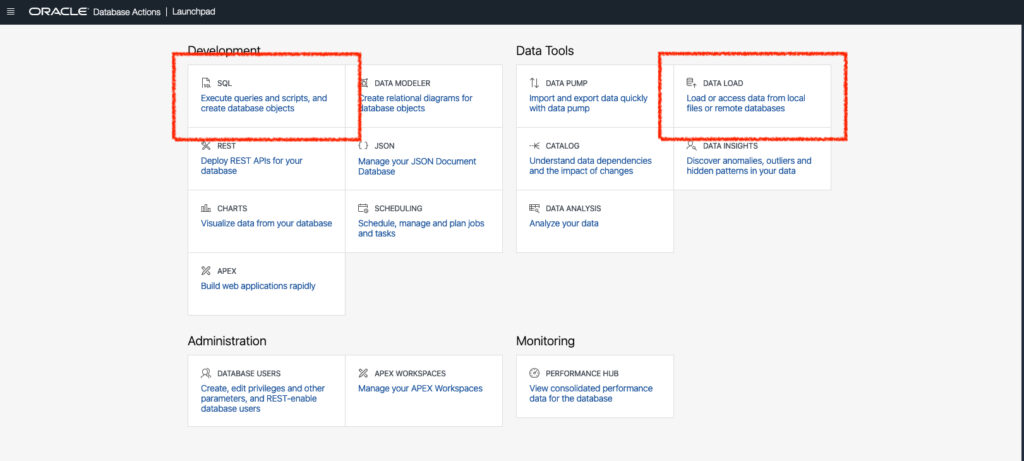
And from what I learned in the Autonomous Database workshop, there are two ways to load data into your database (there may be other methods; mea culpa if so):
- SQL worksheet (found in the Development section, of your launchpad)
- Data Load Tool (found in the Data Tools section)
And I opted for the SQL worksheet method since I need to practice and learn this method regardless.
Obstacles
After choosing my method of data loading, I encountered some obstacles. With no regard for best practices, I proceeded to load all three datasets into my Autonomous Database only to discover two glaring issues.
First
Unfortunately, in my restaurant “violations” table, I encountered two rows that failed to load.
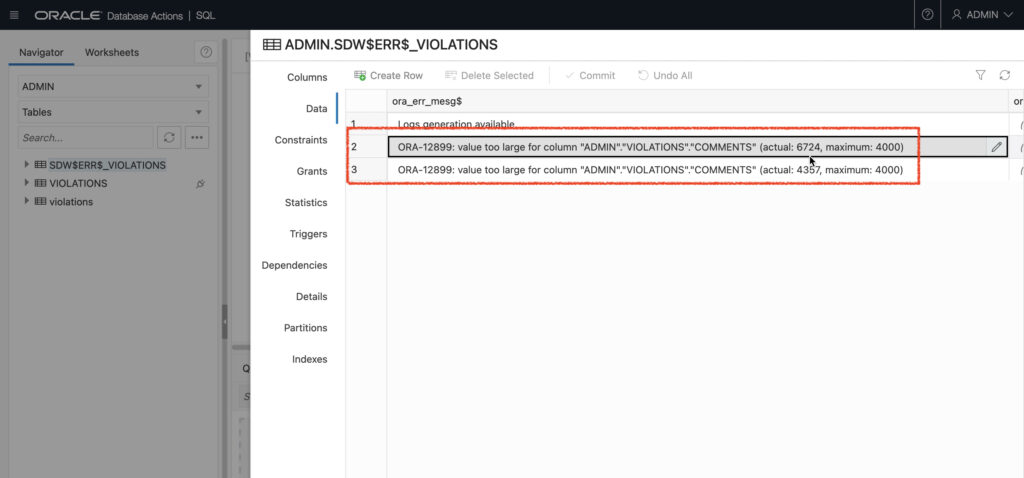
These values were loaded as a VARCHAR2 datatype, which, by default, allows for a maximum byte size of 4000 bytes. Since these rows exceeded 4000 bytes (in that specific column) they failed. Fortunately, it was easy to increase the bytes to 10,000.
While you can increase it to 32,767 bytes, that is overboard. VARCHAR2 data types can have their max string sizes set to ‘STANDARD’ or ‘EXTENDED’ (i.e 4000 bytes vs 32,767 bytes). I’m assuming the Autonomous Database is set to EXTENDED by default, since I was able to increase this column, and re-upload with zero failed rows. You can read up on VARCHAR2 data types here.
Second
The second obstacle I ran into, took me about a day (on and off) to figure out. The dates in all three of these tables were constructed like this:
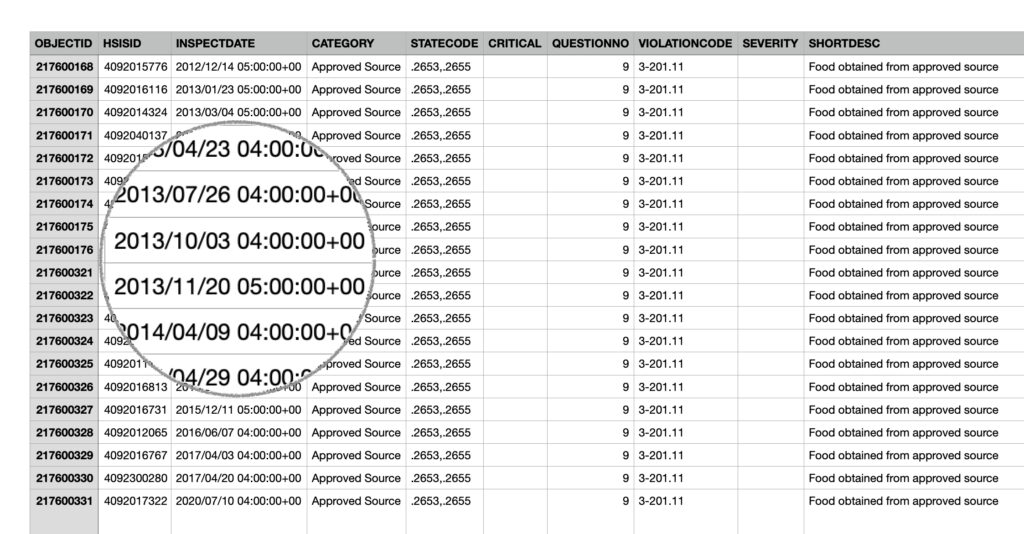
At first glance, I thought I was looking at a time zone offset. Dates were either 04:00:00+00 hrs or 05:00:00+00 hrs; possibly due to daylight savings time. This seemed like a reasonable assumption since the early-November — mid-March dates were an hour later than the mid-March — early-November dates (i.e., UTC-4hrs in Winter, UTC-5hrs all else).
My first thought was to modify the affected columns with something like this parameter:
TIMESTAMP [(fractional_seconds_precision)] WITH TIME ZONEor with…
TIMESTAMP '1997-01-31 09:26:56.66 +02:00'But, I’d never seen this date/time stamp before (the ‘esriFieldTypeDate’), so I had to investigate before I did anything (also, I’ve no idea how to update a column with a parameter like this, so it would have added additional time).
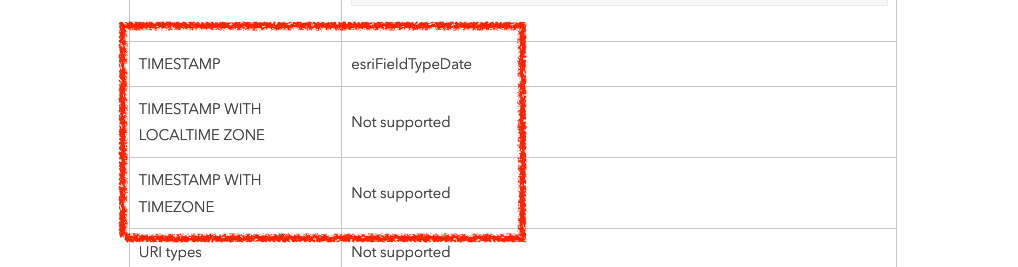
Turns out this data originates from ArcGIS Online. This field data type maps directly to Oracle’s ‘TIMESTAMP’ data type. Seen here in the documentation:
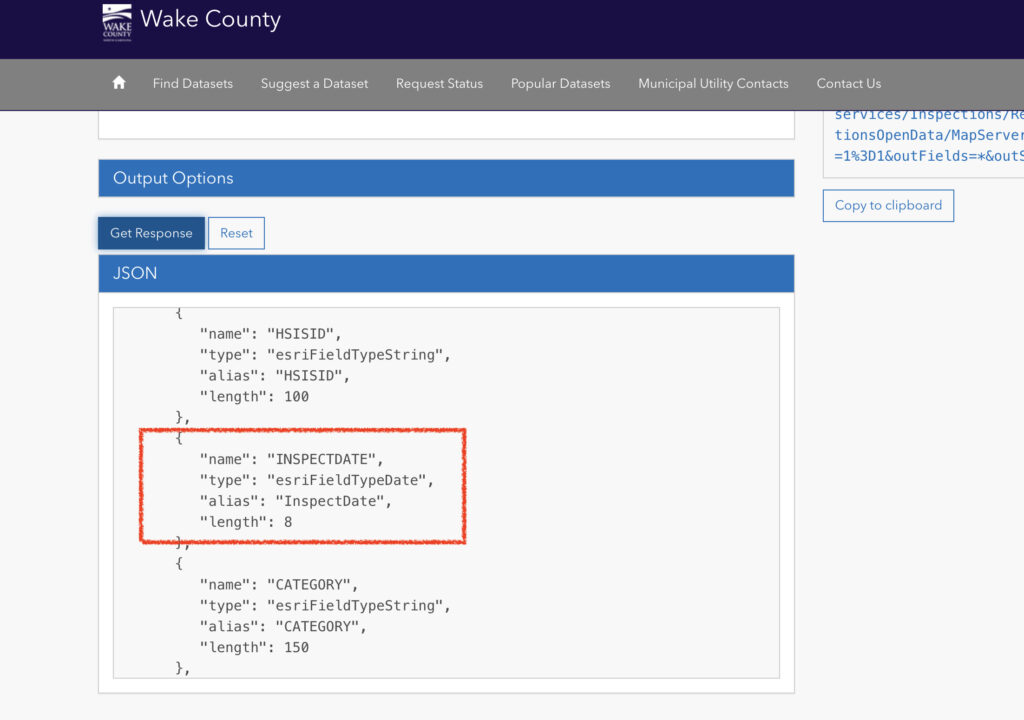
I later tinkered with an API Explorer on the Wake County datasets site and reviewed a sample JSON response for this data set. The response also confirmed the field type:
It’s funny because, after all this hunting, it looks like I won’t be able to include time zones anyways. It’s somewhat inconsequential as I’m only interested in Wake County, but for some that could be unnerving.
I wish I could say that I came up with a cool Python script to automate the cleaning of these columns (I would have had to do this for all three of my .CSV files), but I did not. It would have taken me an afternoon or longer to work through this since I haven’t toyed with .CSV Reader (in the Python standard library), Pandas, or NumPy in quite some time. In the end, (and it pains me to say this, embarrassingly, really), I used the ‘Find + Replace’ feature in Numbers to remove the time/time zone portion of the dates.
I’m pathetic, I know. But the idea of creating a dedicated Python script does seem like a fun weekend project. Who knows, maybe I’ll post to GitHub. Regardless, my Autonomous Database is clean and primed for ORDS.
In closing
In closing
My advice is as such:
Always inspect your data before you do anything major, always make sure you understand the inputs and the resultant outputs of the data loading process, and always refer to the documentation FIRST so you can understand how data is being recorded, coded, displayed, etc..
Chris Hoina, 2022
Oh, and it wouldn’t hurt to think about how you might use this data in the future. I’m guessing that could help you avoid a lot of rework (i.e. technical debt).
Take me as an example. Since I’m focused on ORDS and REST enabling my database, I may want to consider things like:
- What am I going to expose (via REST APIs)? or
- What fields might the presentation layer of my application include?
In my case, a lot of this data will lay dormant, as I might choose to focus on only a few key fields. Of course, anything I create will be simple and basic. But that might not be the case for you.

Find me
And as always, catch me on:
Leave a Reply