Category: Autonomous Database
-
Table Prep: Data loads and time zones
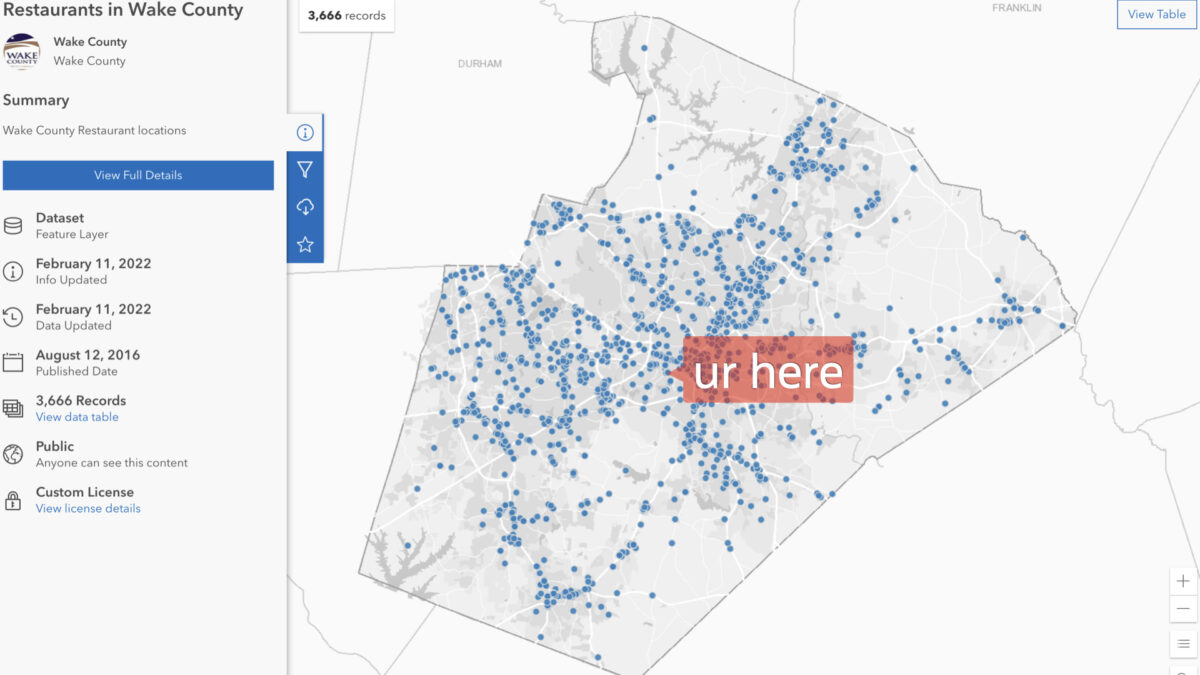
With my Autonomous Database up and running,I needed to find some data to upload.
Written by
-
An Oracle Autonomous Database workshop: here is what I learnt
“…For someone who isn’t familiar with System or Database Administration, this was helpful and it made approaching ‘infrastructure’ so much more accessible and seemingly less daunting…”
Written by
